おはようございます。ロジカル・アーツ株式会社のSE 輪島 幸治です。
Pythonを使用してデータベースとSalesforceを連携するSalesforceインテグレーションの記事を執筆させて頂きます。 目標としては、Pythonプログラムにて、Oracle DatabaseにSQLを実行して取得した結果を加工して、 SalesforceにAPI連携できれば、目標達成としています。
Pythonライブラリを使用することで、実は簡単にSalesforce連携できます。
ブログの記事構成は3部構成となっており、(1)Oracle Databaseインストール方法及びGUI環境構築、 (2)Pythonライブラリインストール・データ取得・インポート、 (3)Pythonを用いたOracle DatabaseとSalesforceの連携という3つの記事構成になっています。
このブログ記事の範囲としては、(2)Pythonライブラリインストール・データ取得・インポートです。 Python環境の構築としてAnaconda、プロダクトとの連携で使用するPythonライブラリとしてSalesforce bulk・cx-Oracle)、 データベースに格納するデータセットとしてscikit-learn datasetsを使用します。
この記事では、AnacondaでPythonの環境構築を行ったのち、追加で専用のPythonライブラリをインストールして、Pythonの実行環境を構築します。また、連携するOracle Databaseにscikit-learnのデータセットをインポートする際に、Oracle SQL Developerという簡単にインポートできるGUIツールを使用しています。
はじめに
この記事の目的
SalesforceはPaaSとして使用できることから、クラウドデータベースとしての機能があります。 その一方でSalesforceは、顧客関係管理であるCRM(Customer Relationship Management)や 営業支援システムであるSFA(Sales Force Automation)などのSaaSとしての強みを持つクラウドアプリケーションです。
既存システムではSalesforceでないシステムが使用されている環境も多いです。 特に、業務が複雑な業種などは、既存のシステム環境を刷新して、すべてのデータをSalesforce管理することは困難です。 このため、外部システムやデータベースから、Salesforceへの連携方法が必要とされています。
この記事では、初心者向けにSalesforce以外のデータベースシステムのうち、 Oracle Databaseに着目して、Pythonプログラムを使用してデータ連携を行う方法について執筆させて頂きます。 この記事はライブラリの紹介が多い記事なので、手順だけ確認したい方は目次のリンクからご確認下さい。
エンジニアの皆様は、合わせて関連する公式のドキュメントもご参照下さい。 連携ライブラリで使用する各種APIに関しては、公式ヘルプ及び公式のTrailheadにモジュールも用意されています。
公式のTrailhead及び公式ヘルプ:
対象者
この記事では、一般的なデータベースを使用しているユーザが、 Webのフロントシステムとの連携を検討した際に、Salesforceを使用したインテグレーションを検討する方向け。 あるいはSalesforceしかエンタープライズアプリケーションを使用したことがない方。 データベースを使用しているユーザが、Salesforceのシステムインテグレーションを検討することを想定しています。
目標
Pythonプログラムにて、データベースからSalesforce連携を行う場合に、設定理解を目標とした記事です。 データベースやSalesforceの設定をする時間がないので、 画像だけで設定概要を知りたいという方が設定方法の流れを知って頂くことも目標としています。 Oracle Databaseのインストール・設定、Pythonアプリケーションのライブラリインストール、 プログラムを使用したSalesforce連携手順を画像付きでご紹介させて頂きます。
Python環境の構築
Anaconda
さて、Anacondaですが、大規模データ予測や予測解析、科学技術計算向けのPythonディストリビューションです。
Jupyter Notebookやscikit-learn、pandasなど多くのPythonパッケージが含まれており、Python環境を構築するのにとても便利です。 Anacondaに含まれる各Pythonパッケージの一部を簡単に紹介させて頂きます。
| Pythonパッケージ名 | 概要 |
|---|---|
| Jupyter Notebook | ブラウザ上でコードを実行できる非常に有用で、有名なGUIツール。Microsoftでは、Microsoft Azure上でも、使用できるMicrosoft Azure ノートブックというサービスも提供されていたそうです。(現在は、Azure Notebooksのプレビュー終了済み) |
| scikit-learn | 機械学習分野における重要なライブラリ、多くのチュートリアルやサンプルコードが提供されている。NumPyとSciPyという2つのPythonパッケージに依存したパッケージである。 |
| Matplotlib | Pythonの科学技術計算向けグラフ描画ライブラリ。この記事では使用しない。 |
| pandas | データ変換・解析を行うライブラリ。DataFrameというデータ構造を使用して、データ処理が行える。 |
Jupyter Notebookなどは、GUIで行えることから敷居も高くありません。 このため、CUIで行われていたスクリプトのコーディングがしやすくなり、 近年多くの場面で使用されてきています。
Python・scikit-learn・機械学習
この記事では、機械学習の範囲には触れませんが、AnacondaでPython環境を構築することで、 Pythonによる機械学習、特徴量分析、自然言語処理など多くの分野のプログラミングを行うことができます。
Anacondaのインストール方法については、Python Japanなどで、 インストール方法が紹介されているためこの記事では、割愛させて頂きます。 機械学習、特徴量分析、自然言語処理などに興味がある方は、オライリーの書籍、Githubなどをご確認下さい。
| 参考リンク | 備考 |
|---|---|
| Windows版Anacondaのインストール: Python環境構築ガイド - python.jp | Anacondaのインストール手順 |
| オライリー・ジャパン発行書籍一覧 | 研究者・エンジニアの方で読んでいる方が多いシリーズの書籍 |
| Pythonではじめる機械学習 - scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎 | 機械学習を学習するのに参考になる書籍 |
| GitHub - amueller/introduction_to_ml_with_python: Notebooks and code for the book "Introduction to Machine Learning with Python | Pythonではじめる機械学習のGithub |
| Python による日本語自然言語処理 | インターネットで公開しているオライリーの入門自然言語処理 |
Pythonライブラリ (Salesforce bulk・cx-Oracle)
この記事では、Oracle DatabaseからSalesforce連携を目的としています。 このため、Oracle Databaseとの連携、Salesforceとの連携で2つのライブラリを使用します。 使用するライブラリですが、Salesforce bulkとcx-Oracleです。
cx-Oracleは、Oracle DatabaseからPythonを使用してデータ連携するライブラリです。 Salesforce bulkは、Salesforceと連携できるPythonライブラリです。 Pythonでは、データベース連携などは多くの連携ライブラリが提供されていますが、 この記事では、公式リポジトリ及び企業によって保守されているライブラリを使用させて頂きます。
cx_Oracleについては、Oracleによって保守されているライブラリであり、 Salesforce bulkについては、Herokuのgithubのリポジトリにて提供されているライブラリです。
使用するPythonライブラリ:
・cx_Oracle - Python Interface for Oracle Database
cx_Oracle is licensed under a BSD license which you can find here. The cx_Oracle project is open source and maintained by Oracle Corp.
cx_Oracleの日本語での使い方などは、以下のブログ記事などを参考にしてみて下さい。
・nkjmkzk.net - pythonからOracleに接続するための拡張モジュール、cx_Oracleの基本的な使い方
パッケージのインストール
この記事でのPythonパッケージのインストールですが、pipを使用して、インストールを行います。
Anacondaを使用いるので、condaなどでもインストールできます。
記事では、condaコマンドではなくpipコマンドを使用しています。(気になる方はこちらもご確認下さい。)
フォルダ作成
まず、パッケージのインストールする前に、コンソールログを保存するフォルダを作成します。
この記事では、AnacondaInstallPackageというフォルダ名でC:\Users\***ユーザー名**\Documents配下に作成します。
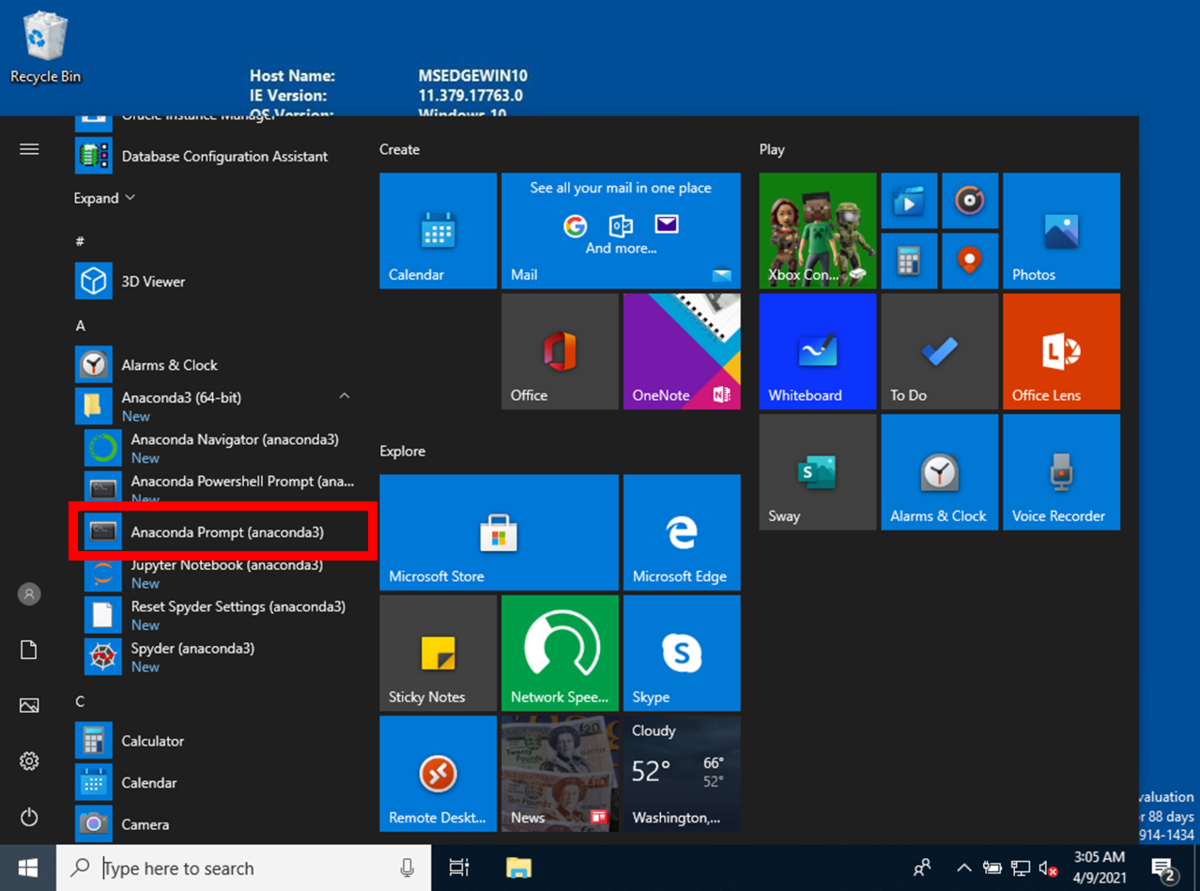
Anaconda Promptの起動
Anacondaで使用しているPythonにパッケージをインストールするために、 Windows 10のスタートメニューから、[Anaconda Prompt(anaconda3)]を選択して、押下します。
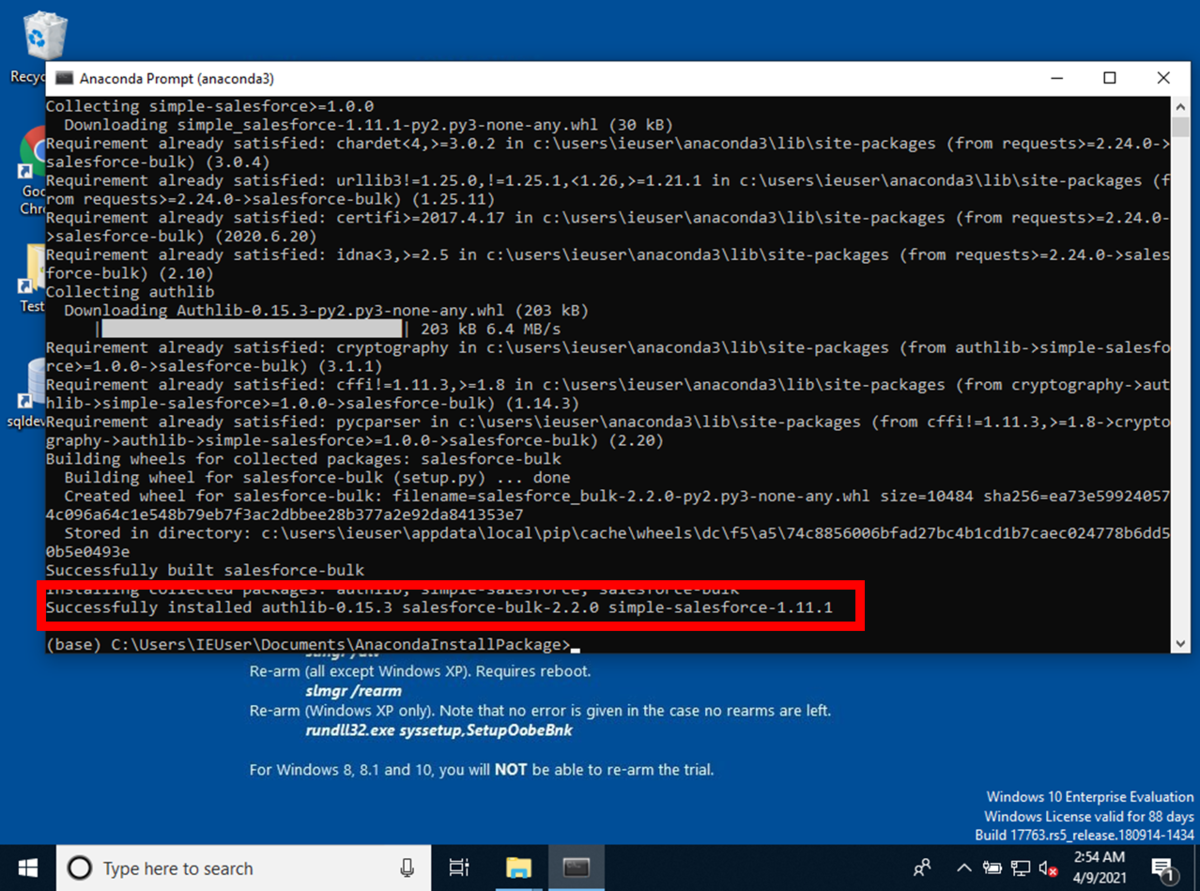
Salesforce bulk インストール
Anaconda Promptが起動したら作成したフォルダに移動して、
salesforce-bulkをpipコマンドを使用してインストールします。
| コマンド概要 | コマンド |
|---|---|
| フォルダ移動 | cd "C:\Users\IEUser\Documents\AnacondaInstallPackage" |
| インストールコマンド | pip install salesforce-bulk |
コマンドで実行したコンソールの結果を保存して下さい。
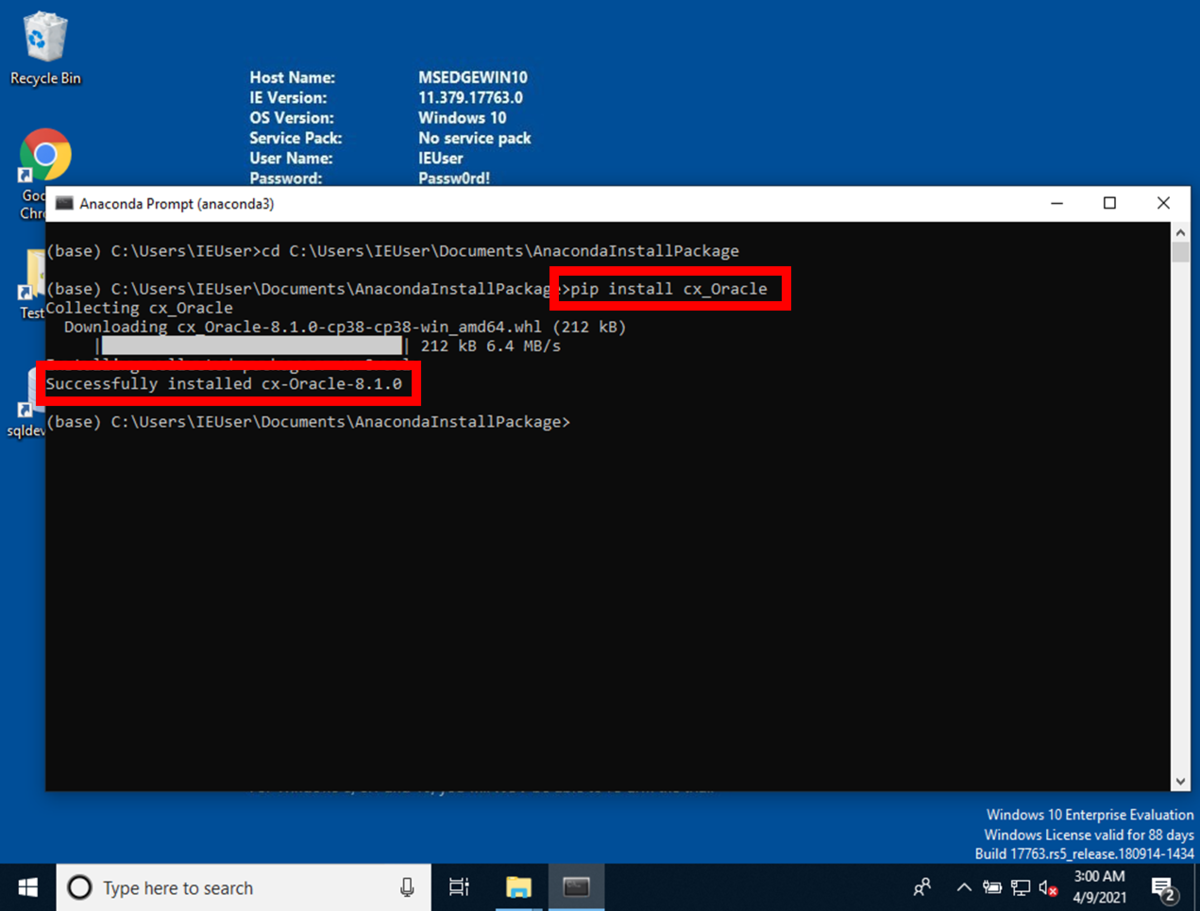
cx-Oracle インストール
salesforce-bulkと同様にcx-Oracleをpipコマンドを使用してインストールします。
| コマンド概要 | コマンド |
|---|---|
| フォルダ移動 | cd "C:\Users\IEUser\Documents\AnacondaInstallPackage" |
| インストールコマンド | pip install cx-Oracle |
コマンドで実行したコンソールの結果を保存して下さい。 cx-Oracleのpipコマンドはこちら、 condaコマンドはこちらを、必要に応じて参照して下さい。
※cx-Oracleは、「Pythonを使用したデータベースとSalesforceの連携方法(3)」で使用します。
インストールログの保存
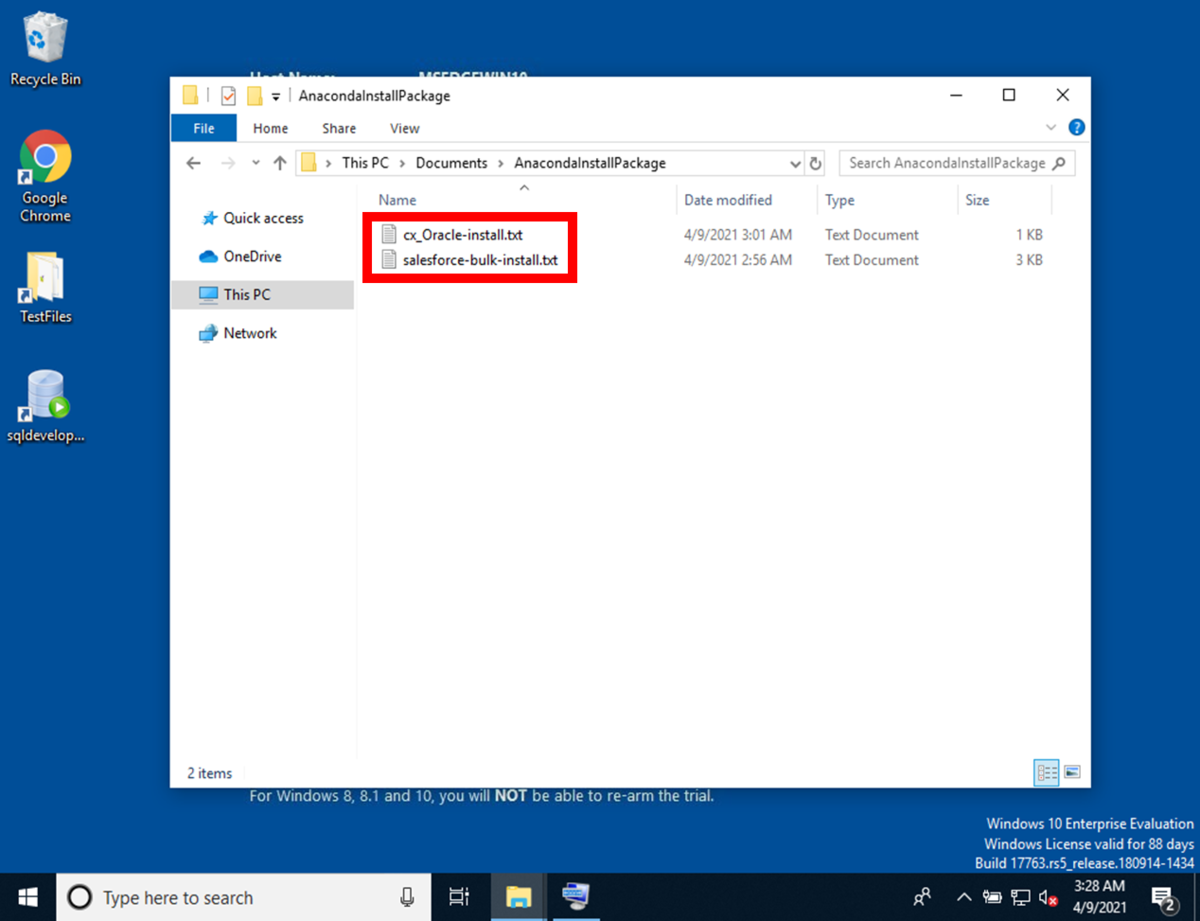
コマンド実行した結果を、テキストファイルにして、
AnacondaInstallPackageフォルダに格納しておきます。
データ取得・インポート
次に、Oracle Databaseにインポートを行うデータの用意をします。この記事では、scikit-learnからthe California housing datasetと呼ばれるカリフォルニア地区の住宅価格のデータセットを取得するプログラムを使用します。
使用方法としては、プログラムを作成するディレクトリに、保存フォルダのdatasetフォルダを作成して、Jupyter Notebookでソースコードを実行すると、保存フォルダにCSVファイルが保存されます。
この記事は、Salesforce連携用のデータベース構築が目的となりますので、Jupyter Notebookで、プログラムを実行する手順のみをご紹介させて頂きます。
scikit-learnからのデータセット取得
scikit-learn datasets
scikit-learnは、機械学習分野のライブラリですが、機械学習用のDataset提供されています。 scikit-learnのDatasetでは、7種類のToy datasets及び9種類のReal world datasetsという合計16種類のデータセットが提供されています。 この記事では、scikit-learnのデータセットをCSV形式でファイルを保存して、データベースに格納して使用します。
scikit-learn -7. Dataset loading utilities
データはCSV形式で提供されている訳ではありませんので、 Pythonスクリプトを作成して、CSVファイルに変換してから使用します。
データセット取得ソースコード
#dataset import
from sklearn.datasets import fetch_california_housing
#load dataset
housing = fetch_california_housing()
#dataset
housing
#pandas import
import pandas as pd
#make pandas dataframe
dataframe_california_housing = pd.DataFrame(housing.data, columns=housing.feature_names)
#pandas dataframe
dataframe_california_housing
#save dataset(csv)
dataframe_california_housing.to_csv('./dataset/sklearn_california_housing.csv')
Jupyter Notebookで行うscikit-learnデータの取得と変換
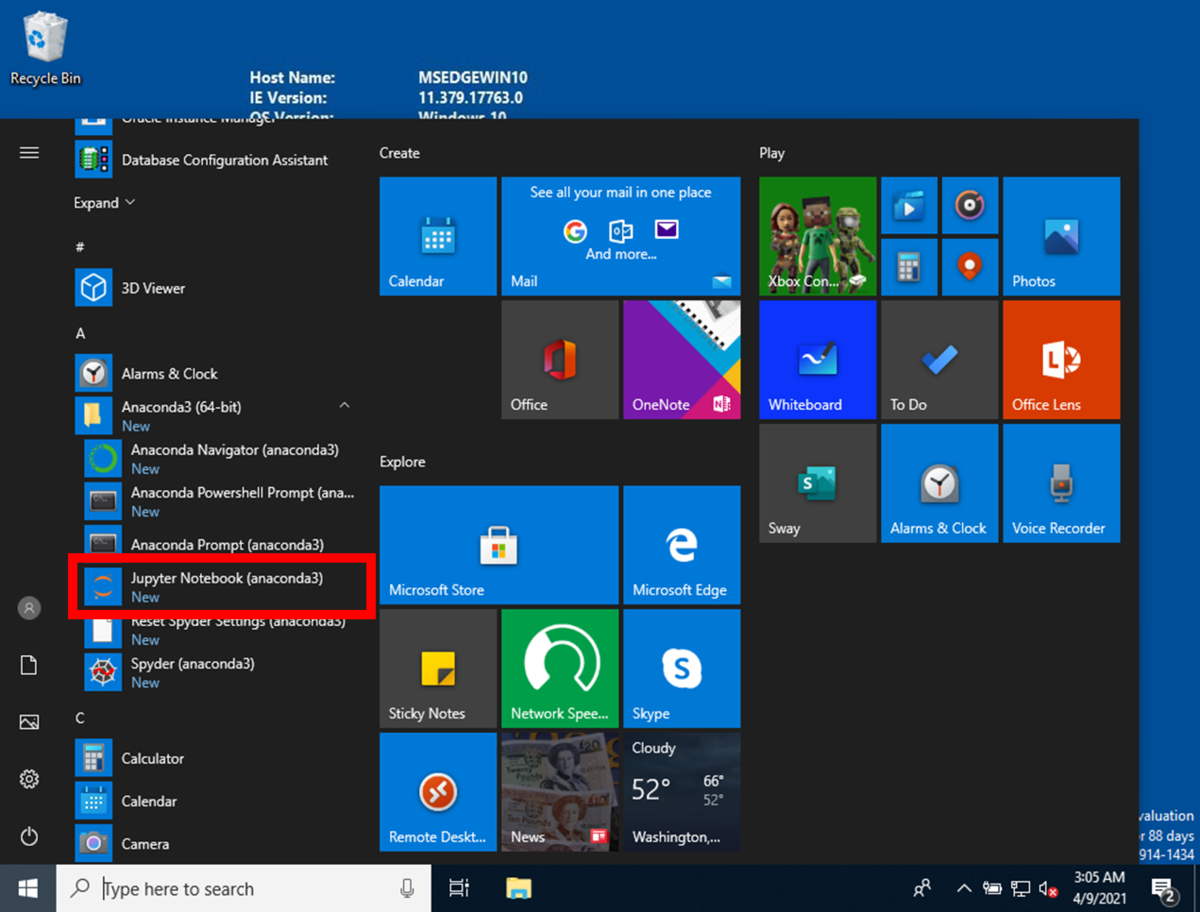
スタートメニューを押下して、[Jupyter Notebook (anaconda3)]を押下して、Jupyter Notebookを起動します。
Jupyter Notebookが起動して、ブラウザが起動しましたら、Pythonスクリプトを保存するディレクトリに移動します。 今回は、マイドキュメント配下に作成される[Python Scripts]フォルダを使用します。 [Python Scripts]フォルダに作成するPythonスクリプトを保存します。
| 種別 | 項目値 |
|---|---|
| URL | http://localhost:8888/tree/Documents/Python Scripts/ |
| ディレクトリ表記の場合 | C:\Users\{**ユーザー名**}\Documents\Python Scripts\ |

Jupyter Notebookの画面右にある[New]ボタンを押下して[Python 3]を選択して押下します。
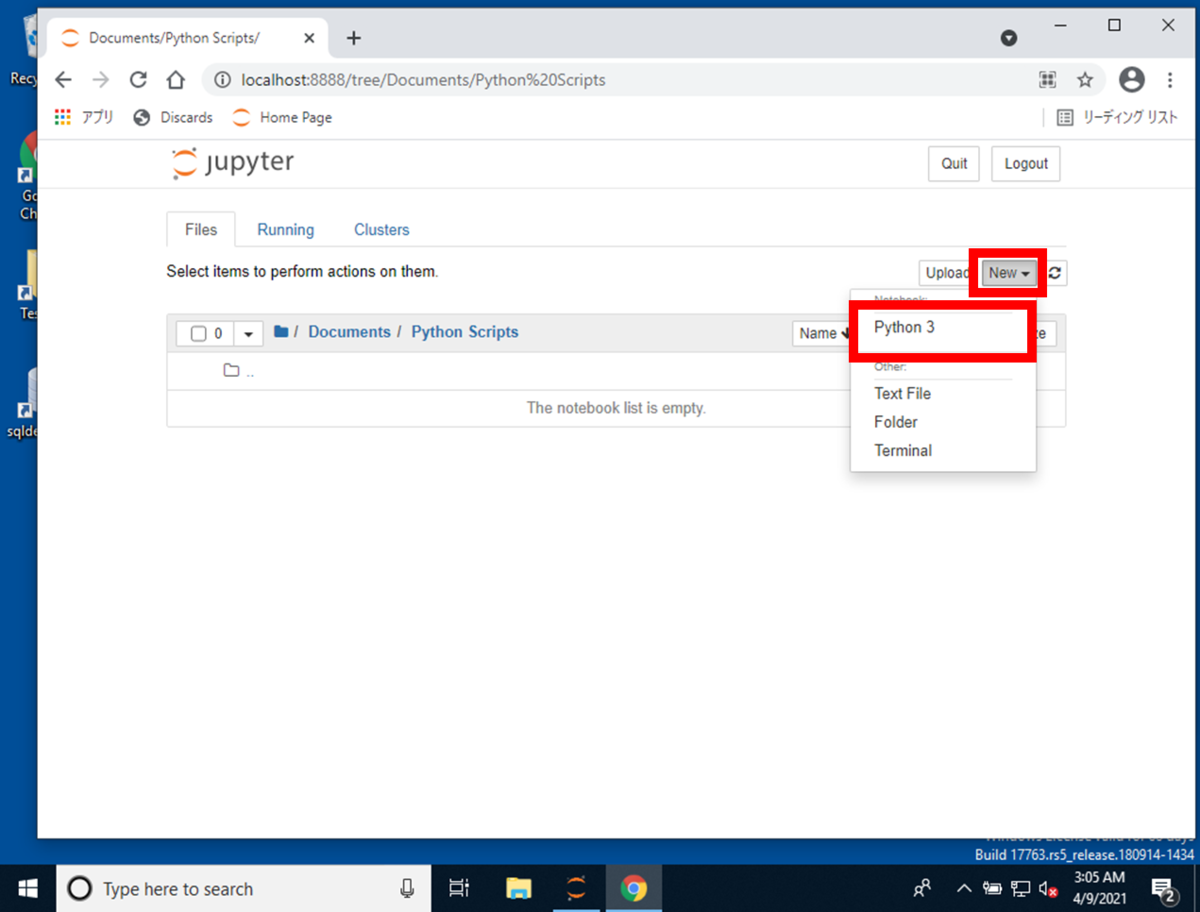
新しいタブで、Jupyter NotebookのPythonスクリプト作成画面が表示されます。
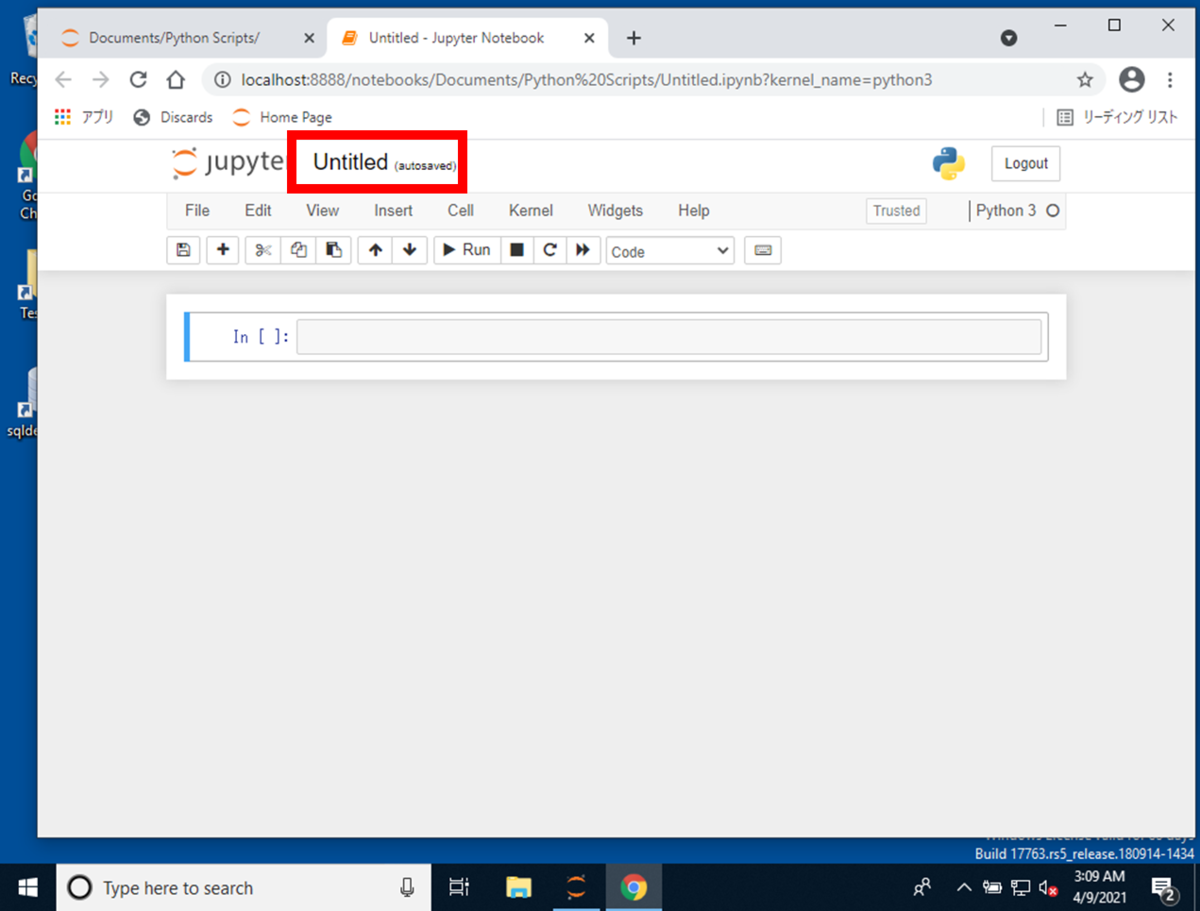
Pythonスクリプトが作成されると、デフォルトのファイル名に[Untitled]と表示されています。
[Untitled]の入力フォームを押下するとファイル名が変更できますので、入力フォームを押下します。
入力フォームを押下すると、[Rename Notebook]が表示されますので、 Pythonスクリプト名を入力して、[Rename]を押下します。
今回は、sklearn_datasets_downloadと入力して、[Rename]を押下します。
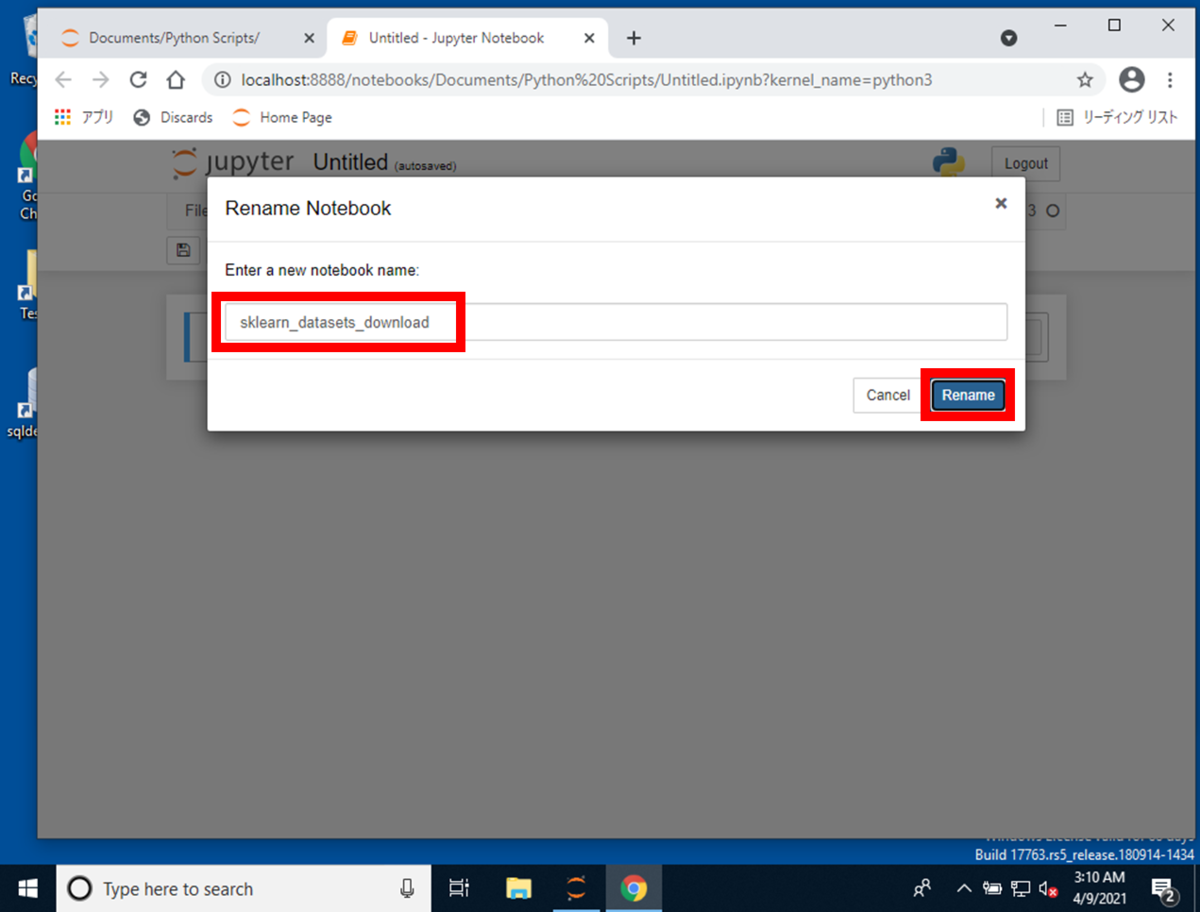
ファイル名が変更されますので、In[]: と表示されている箇所にソースコードの使用箇所(1)を使用してPythonスクリプトとして実行します。Pythonを実行すると、scikit-learnからthe California housingのデータがJupyter Notebook上で表示されます。
ソースコード使用箇所(1):
#dataset import from sklearn.datasets import fetch_california_housing #load dataset housing = fetch_california_housing() #dataset housing
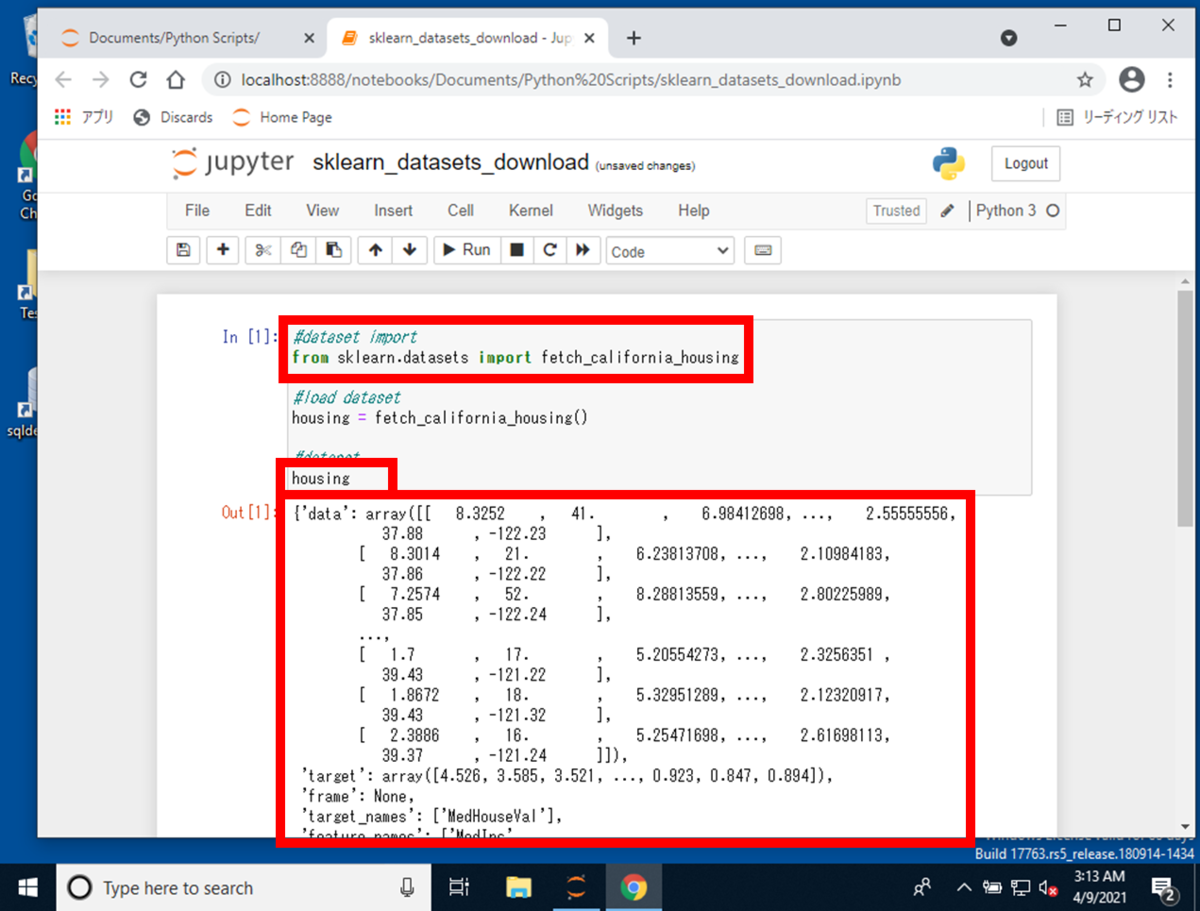
表示されたデータは、取得したthe California housingのデータが表示されているのみです。 次に、CSVファイルに変換するために、ソースコード使用箇所(2)を使用して、pandasのデータフレームに変換します。
ソースコード使用箇所(2):
#pandas import import pandas as pd #make pandas dataframe dataframe_california_housing = pd.DataFrame(housing.data, columns=housing.feature_names) #pandas dataframe dataframe_california_housing
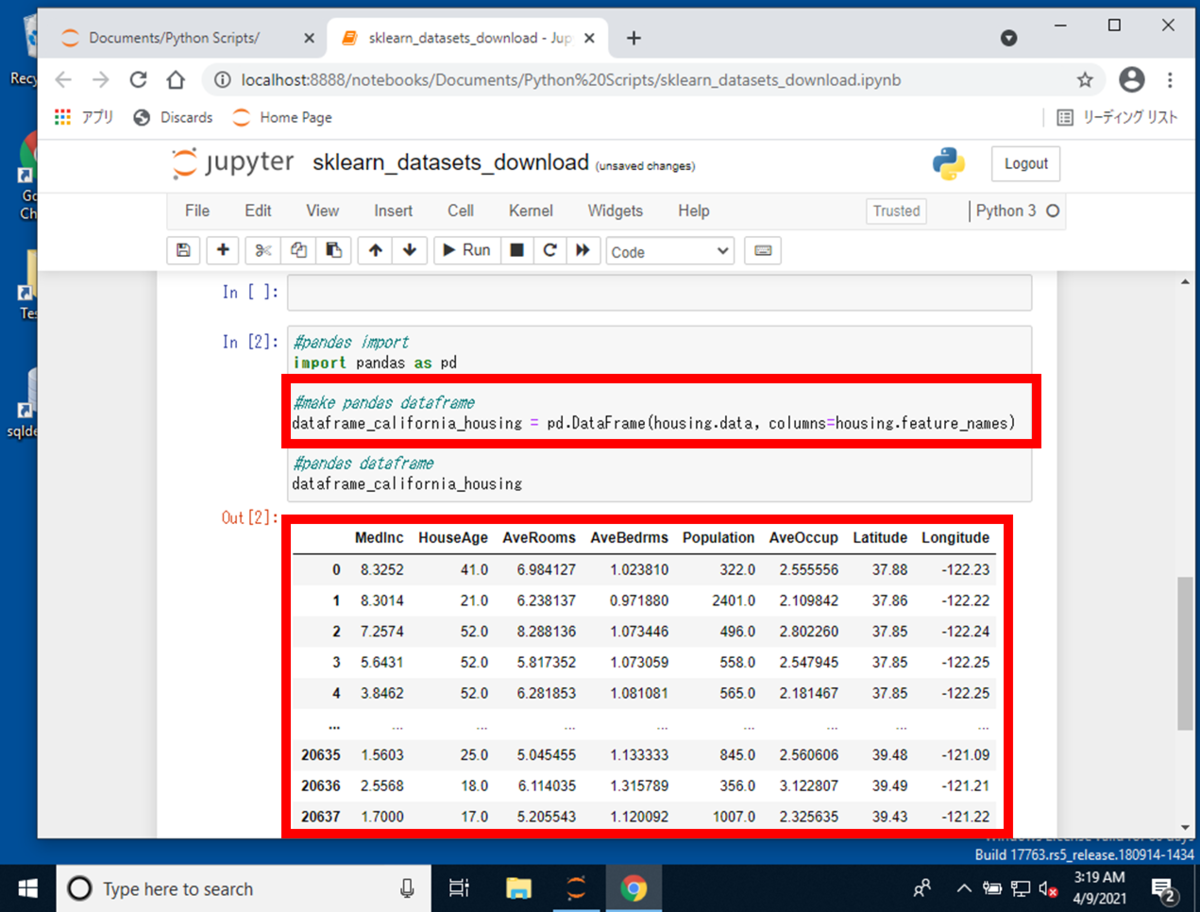
pandasのデータフレームに変換されたことを確認して、次は保存ディレクトリを作成します。
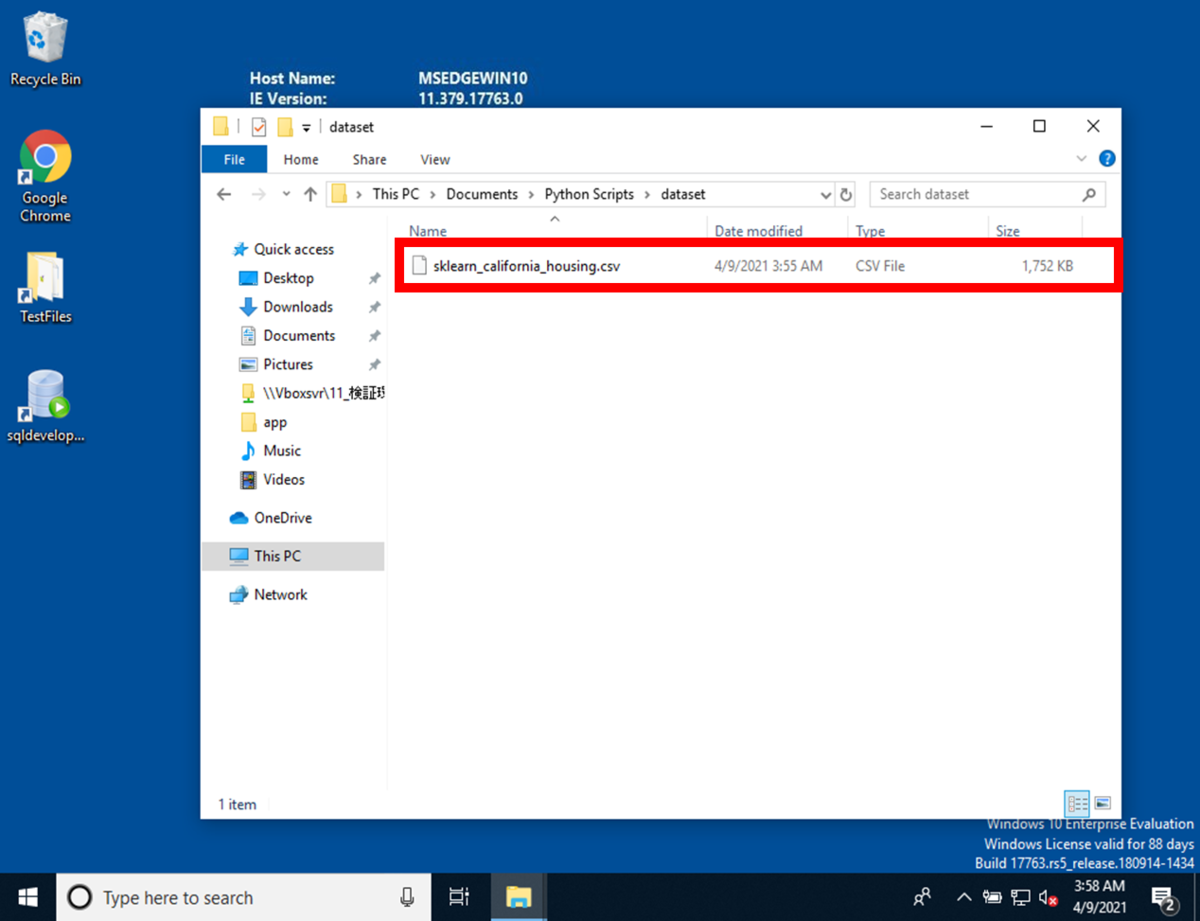
データフレームをCSVに変換した際に保存するためのディレクトリをPythonスクリプトと同じディレクトリに作成します。
保存ディレクトリのフォルダ名をdatasetとして作成して下さい。
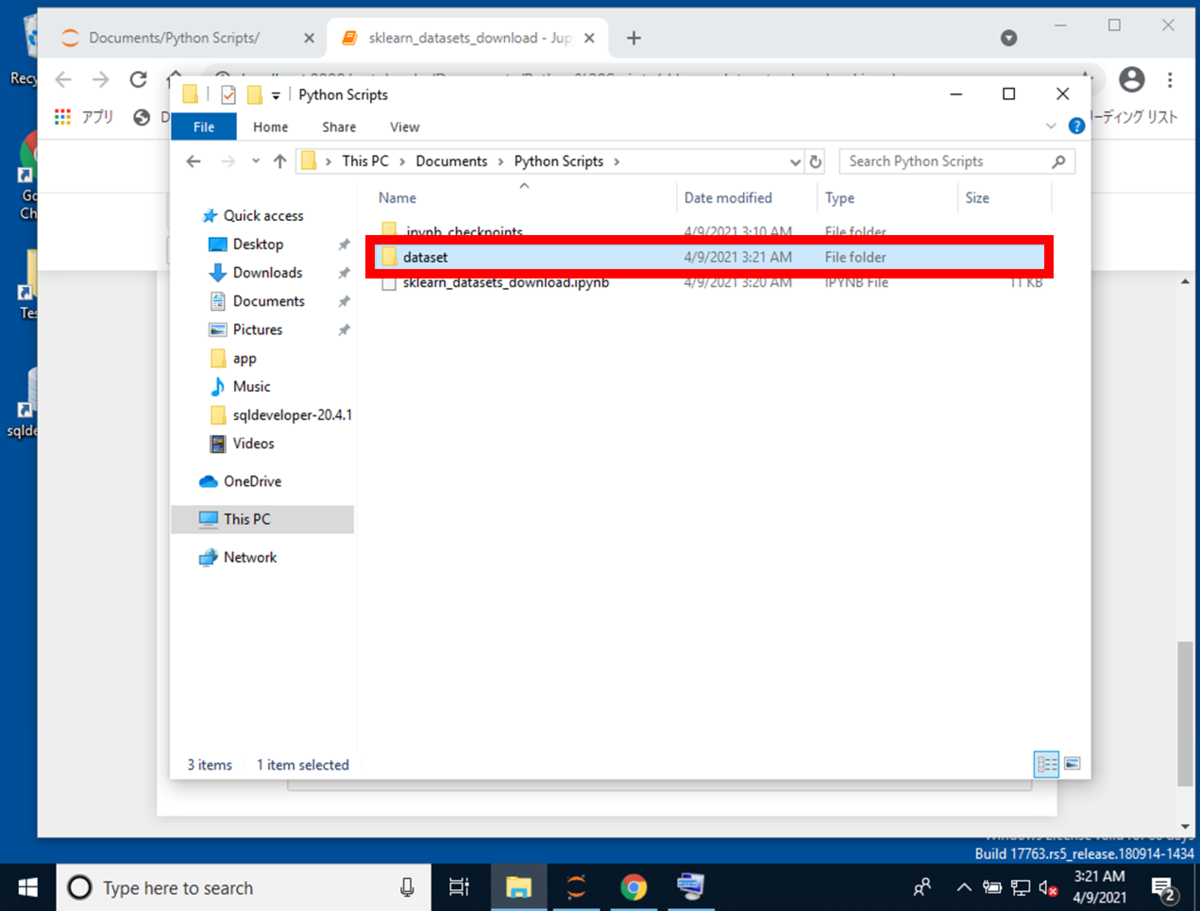
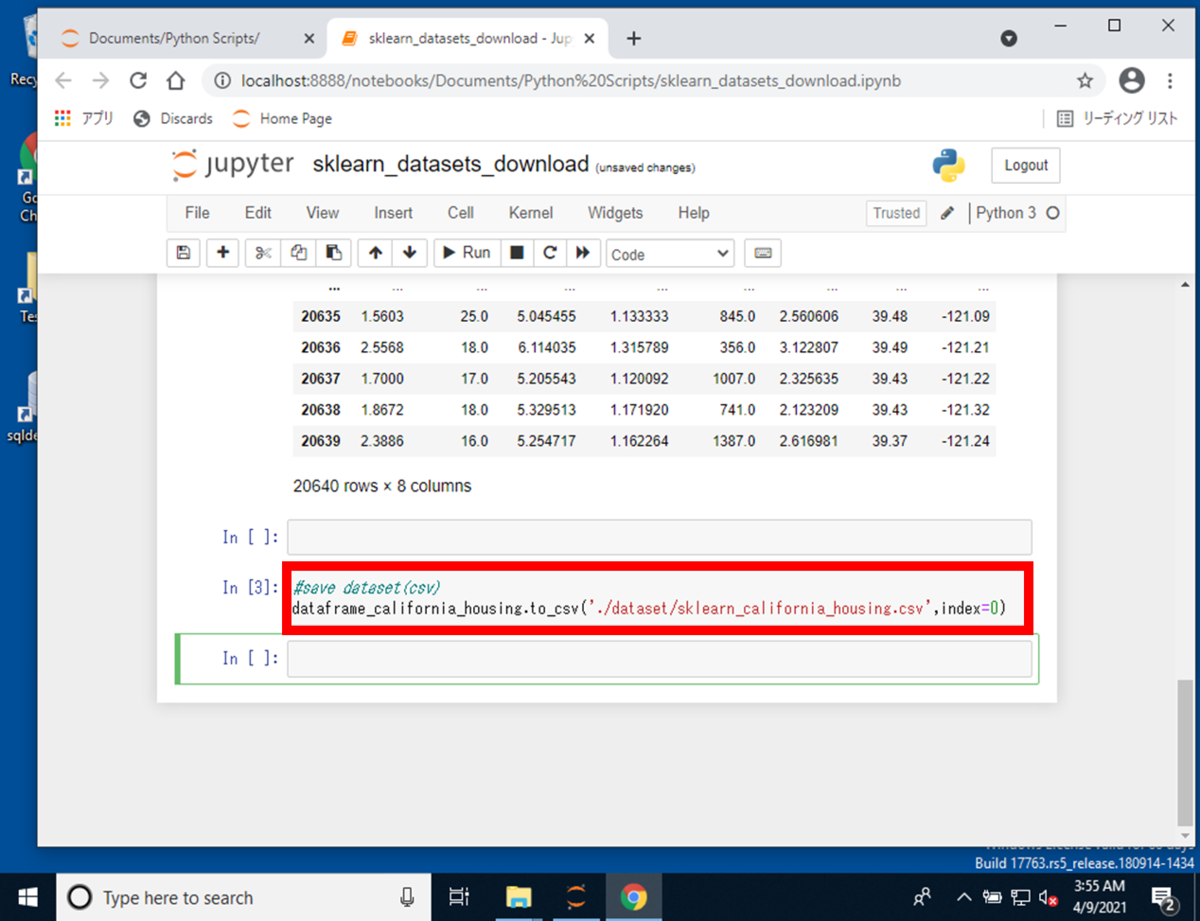
データフレームをCSVファイルに変換するPythonスクリプトを実行すると、 実行後、作成したdatasetフォルダに、CSVファイルが作成されていることが確認できます。
ソースコード使用箇所(3):
#save dataset(csv)
dataframe_california_housing.to_csv('./dataset/sklearn_california_housing.csv')
Oracle SQL Developer
Pythonプログラムで作成したCSVファイルをOracle SQL Developerを使用して、Oracle Databaseにインポートする手順を紹介させて頂きます。

まず、デスクトップのショートカットから、Oracle Databaseを起動します。
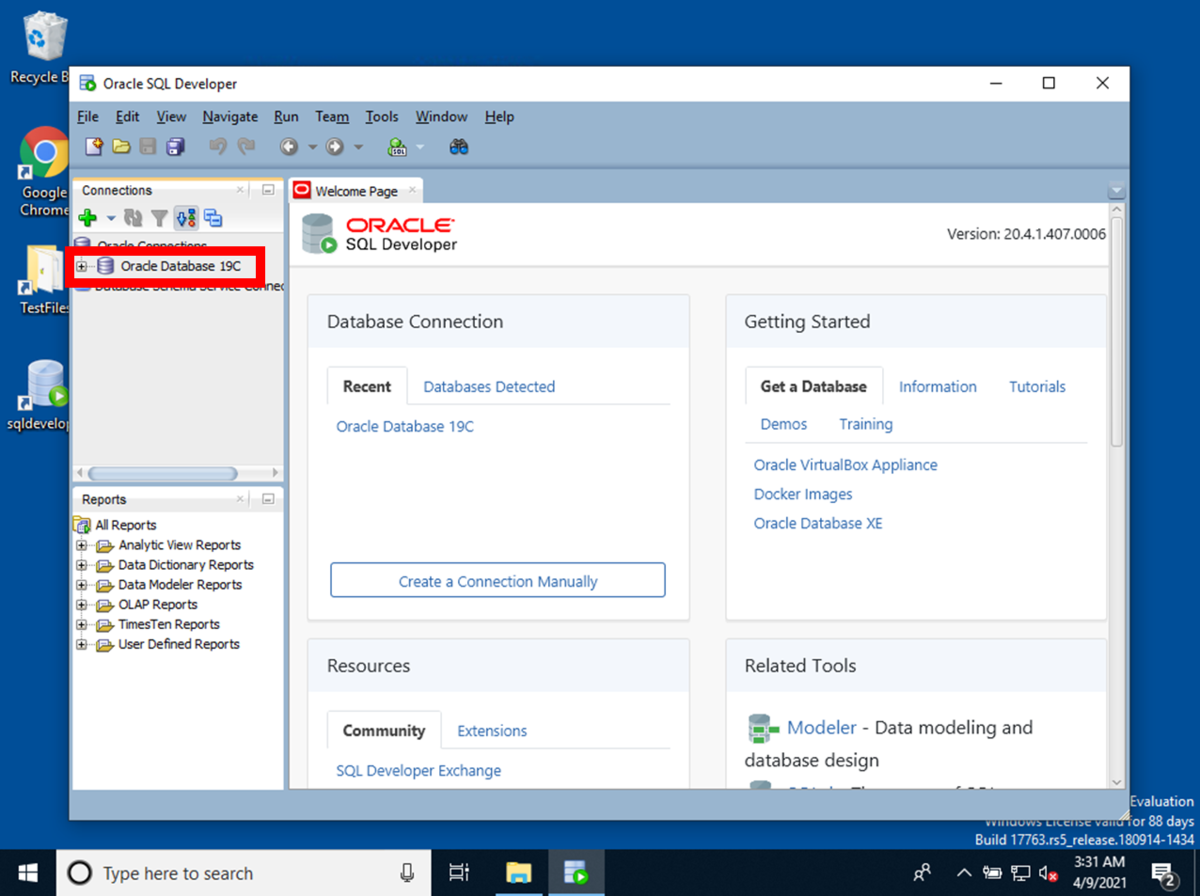
Connectionsにある接続設定済みのデータベース(今回は、Oracle Database 19C)から、CSVをインポートするデータベースに接続します。
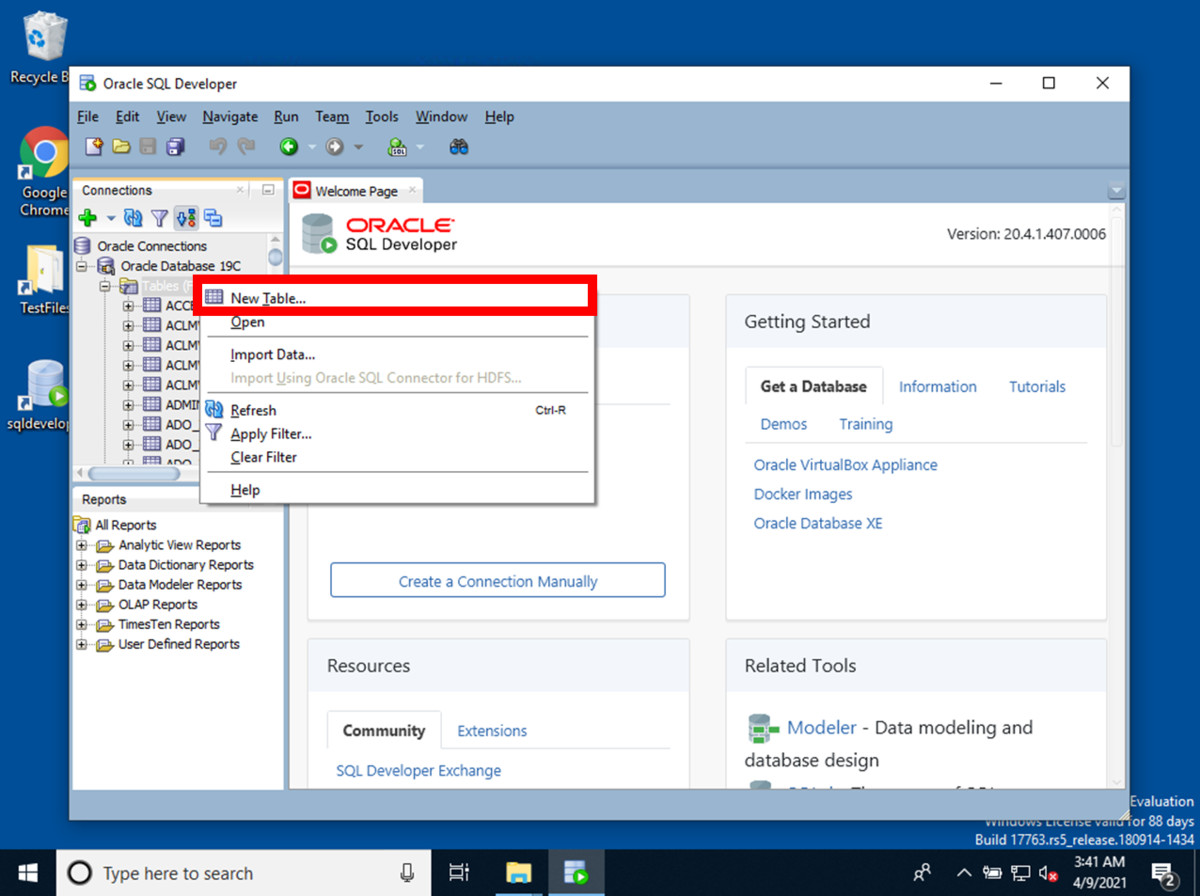
[Tables (Filtered)]を選択して、右クリックを押下して、[New Table]を押下します。
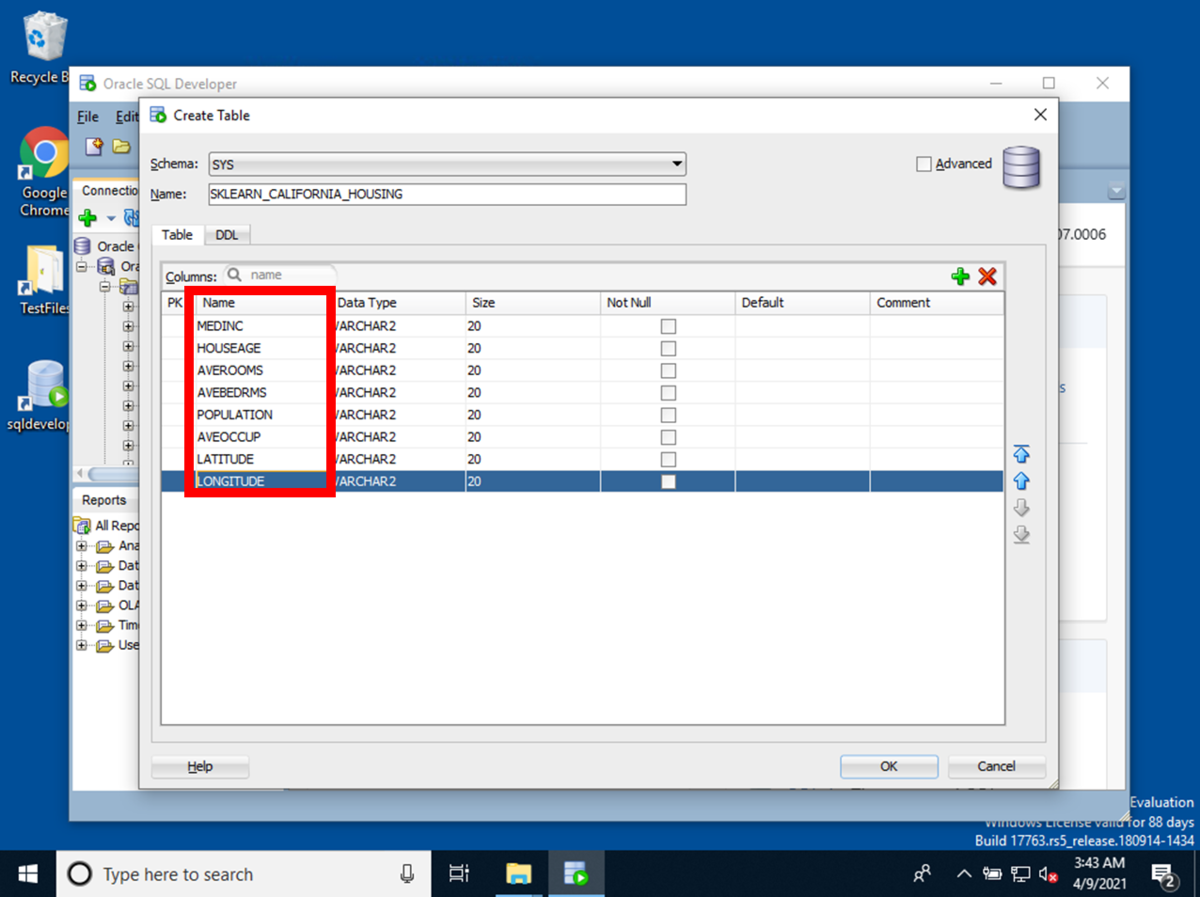
the California housing datasetの項目名と同じ項目名で、データベースの項目を作成します。
データベースのNameをthe California housing datasetの項目名と同じ小文字項目名にしたい場合は、
[']を入力項目名に設定して下さい。
テーブル名:
SKLEARN_CALIFORNIA_HOUSING
データベースの項目名:
| Name | Data Type | Size |
|---|---|---|
MEDINC |
VERCHAR2 |
20 |
HOUSEAGE |
VERCHAR2 |
20 |
AVEROOMS |
VERCHAR2 |
20 |
AVEBEDRMS |
VERCHAR2 |
20 |
POPULATION |
VERCHAR2 |
20 |
AVEOCCUP |
VERCHAR2 |
20 |
LATITUDE |
VERCHAR2 |
20 |
LONGITUDE |
VERCHAR2 |
20 |
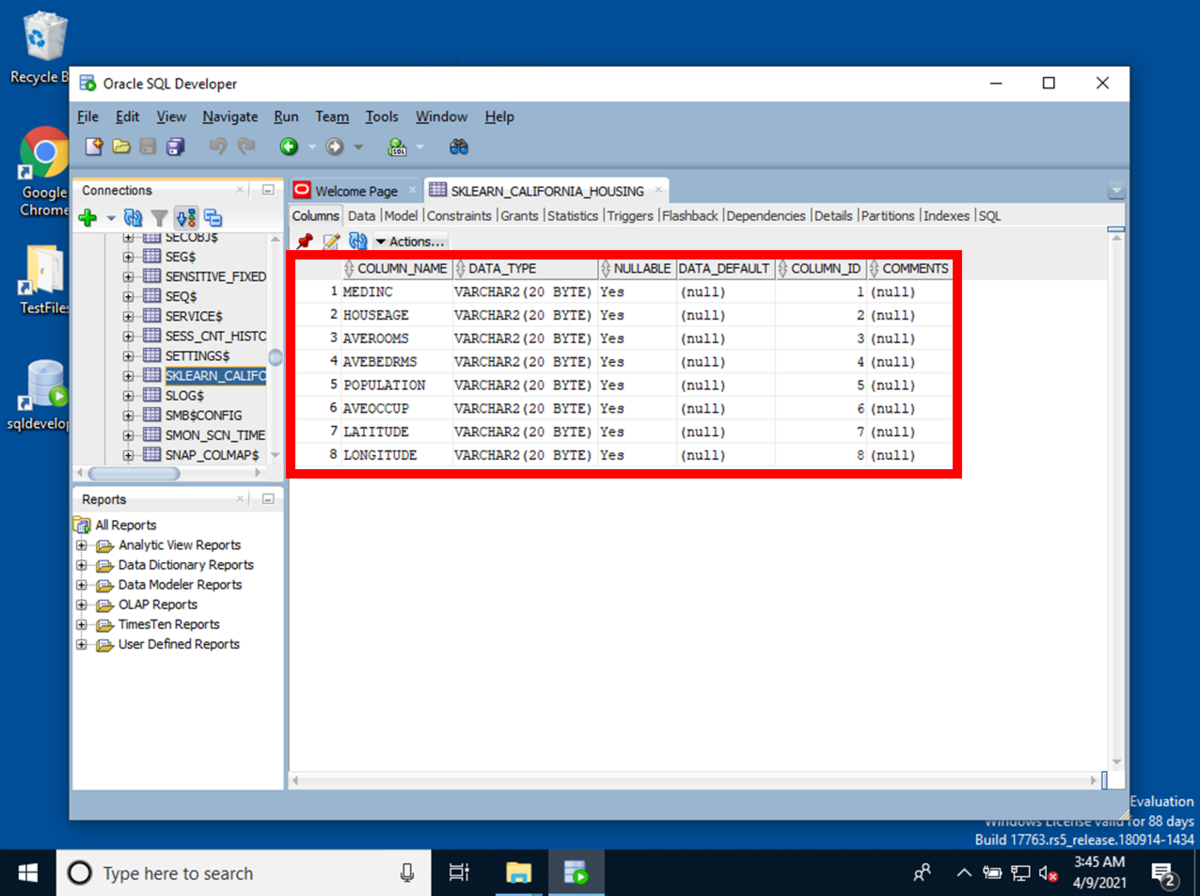
データベース及びデータベースの項目の設定が完成したら、CSVファイルをインポートします。
[SKLEARN_CALIFORNIA_HOUSING]テーブルの[Data]タブにある[Actions]を押下します。
[Actions]を押下すると、[Import Data]を押下します。
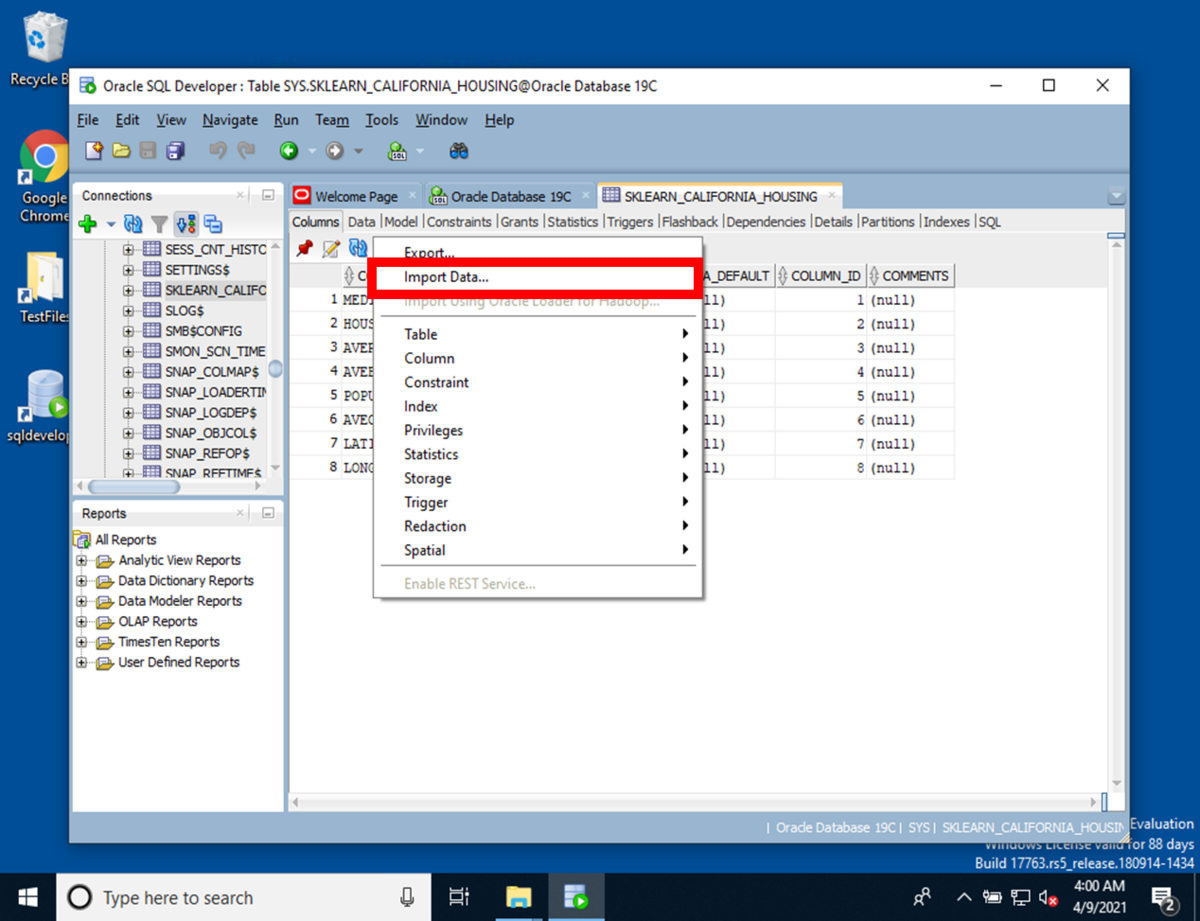
[Step 1 of 5]のData Preview画面にて、[Browse]を押下してインポートするCSVファイルを指定します。インポートするCSVには、Pythonプログラムで作成したthe California housing dataset(sklearn_california_housing.csv)のCSVファイルを指定します。指定するとCSVファイルが表示されますので、[Next]を押下します。
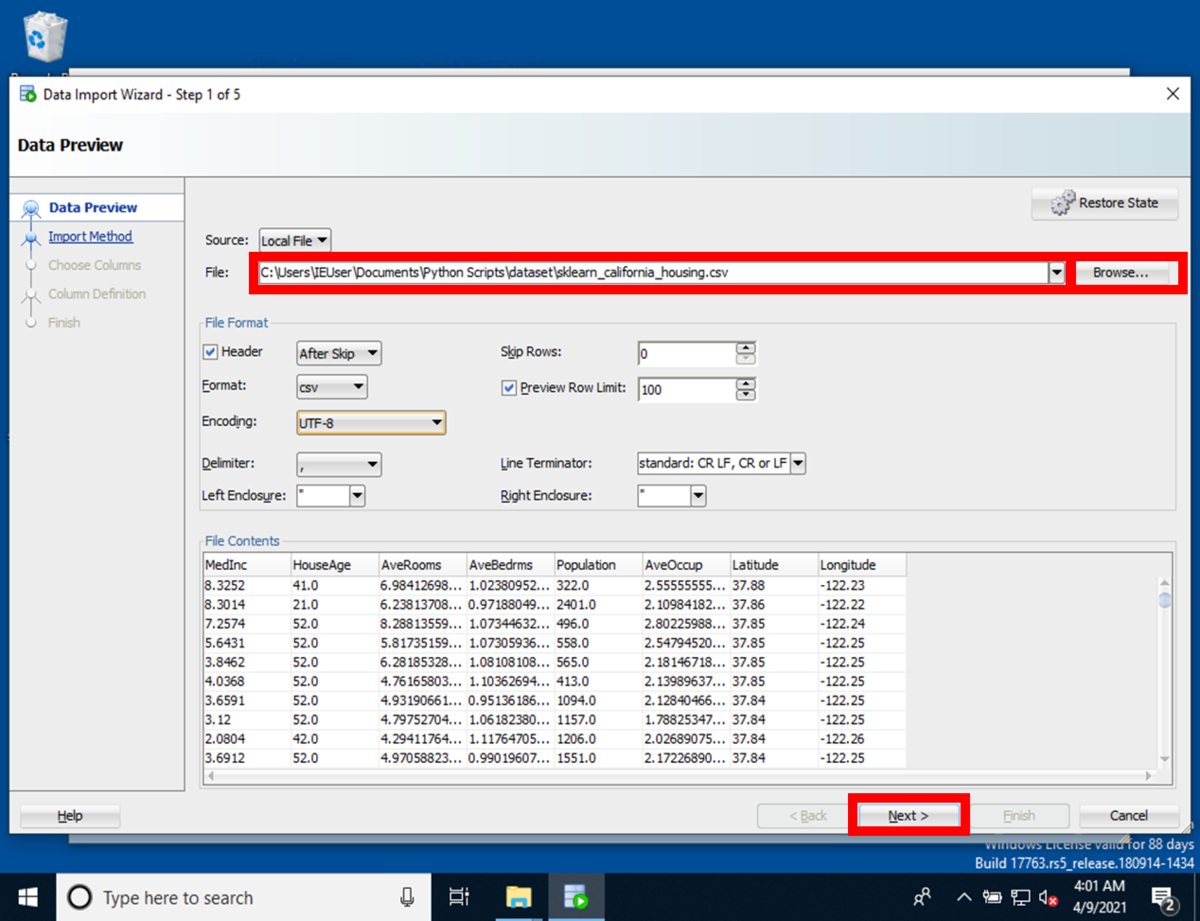
[Step 2 of 5]のImport Method画面にて指定したインポート予定のCSVファイルのレコードが一覧表示されます。
一覧表示されたCSVファイルを確認して[Next]を押下します。
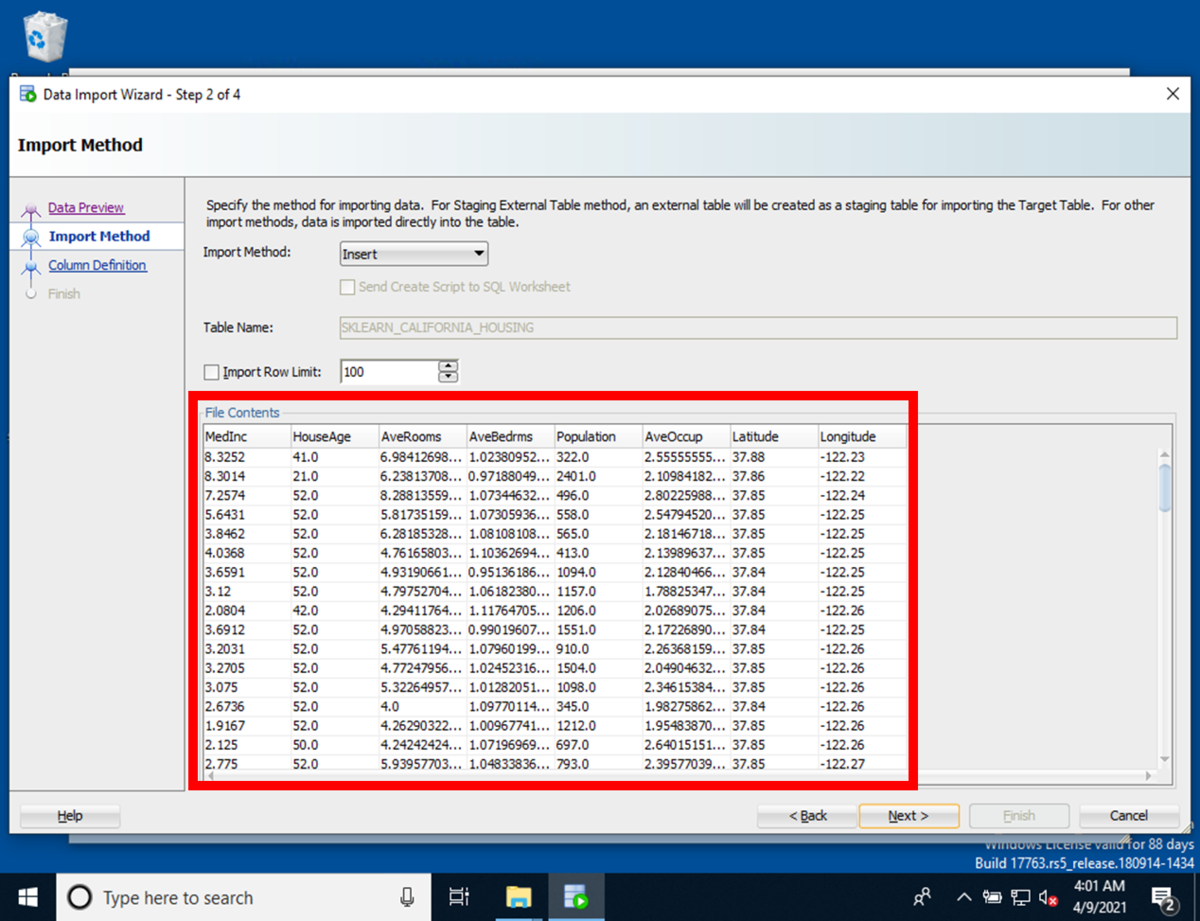
[Step 3 of 5]のChoose Columns画面にて、CSVファイルの列名でインポート対象の列を[Selected Columns]にて指定して、[Next]を押下します。
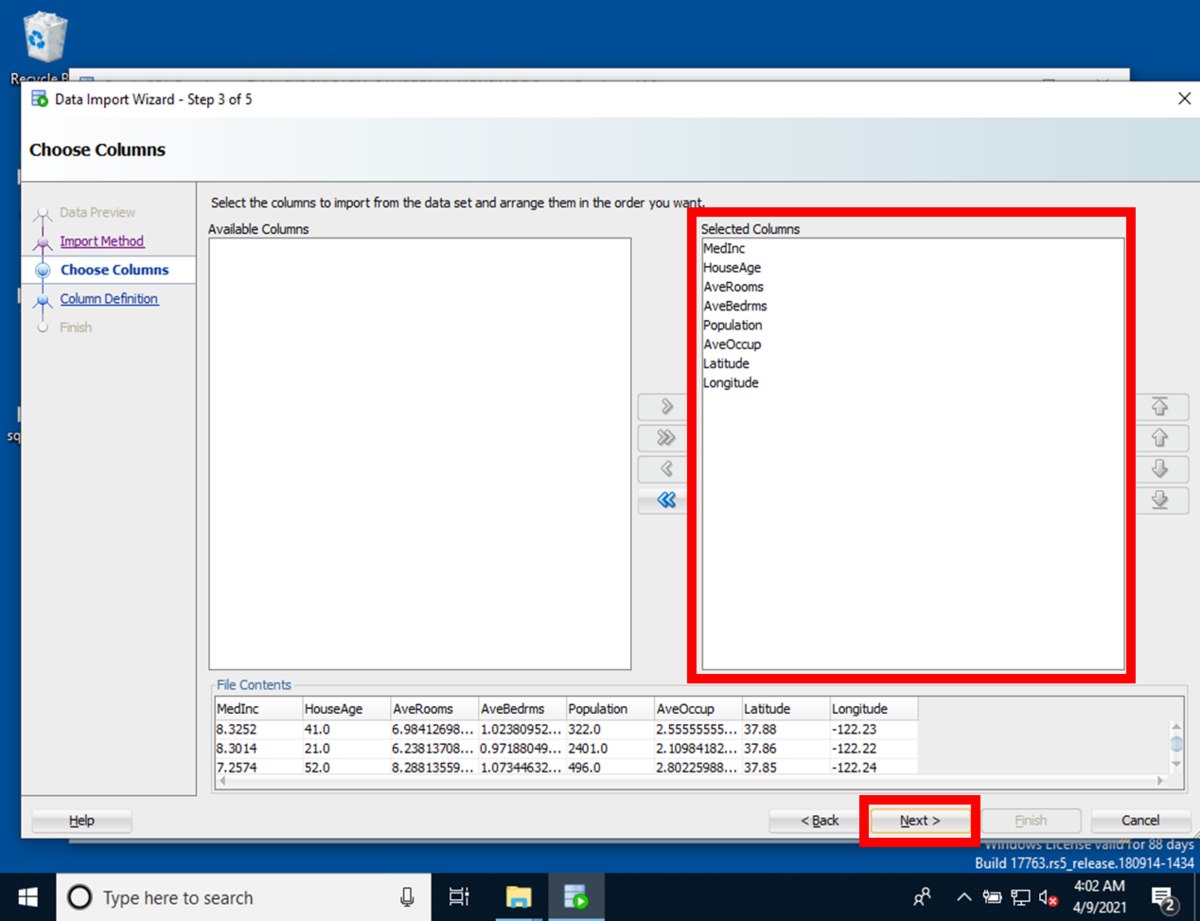
[Step 4 of 5]のColumn Definition画面にて、CSVの項目とデータベースの項目名を一致させます。
各Source Data ColumnsのTarget Table Columnsを指定してインポートするCSVの項目と、データベースの項目名が一致するように指定します。
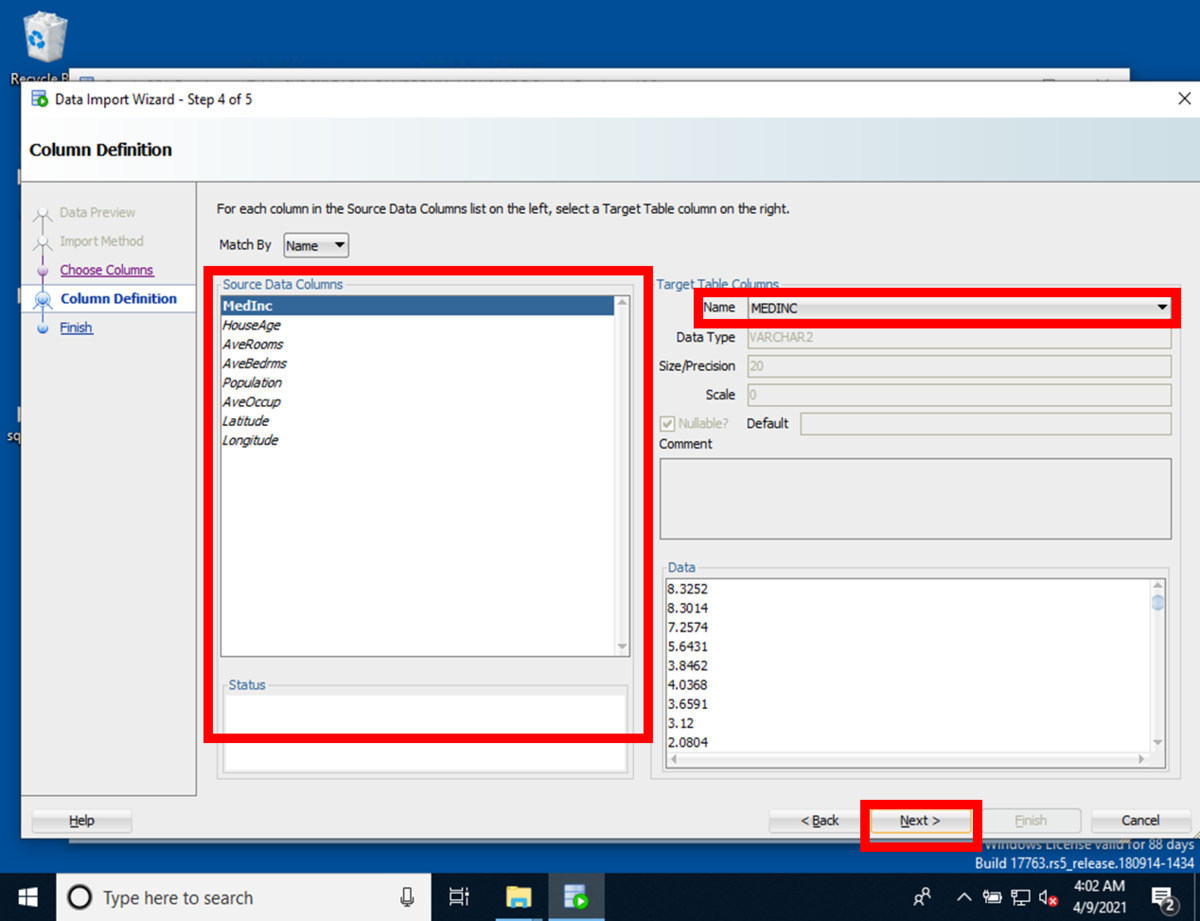
[Step 5 of 5]のFinish画面にて[Finish]を押下すると、インポートが開始され、CSVデータがデータベースにインポートされます。
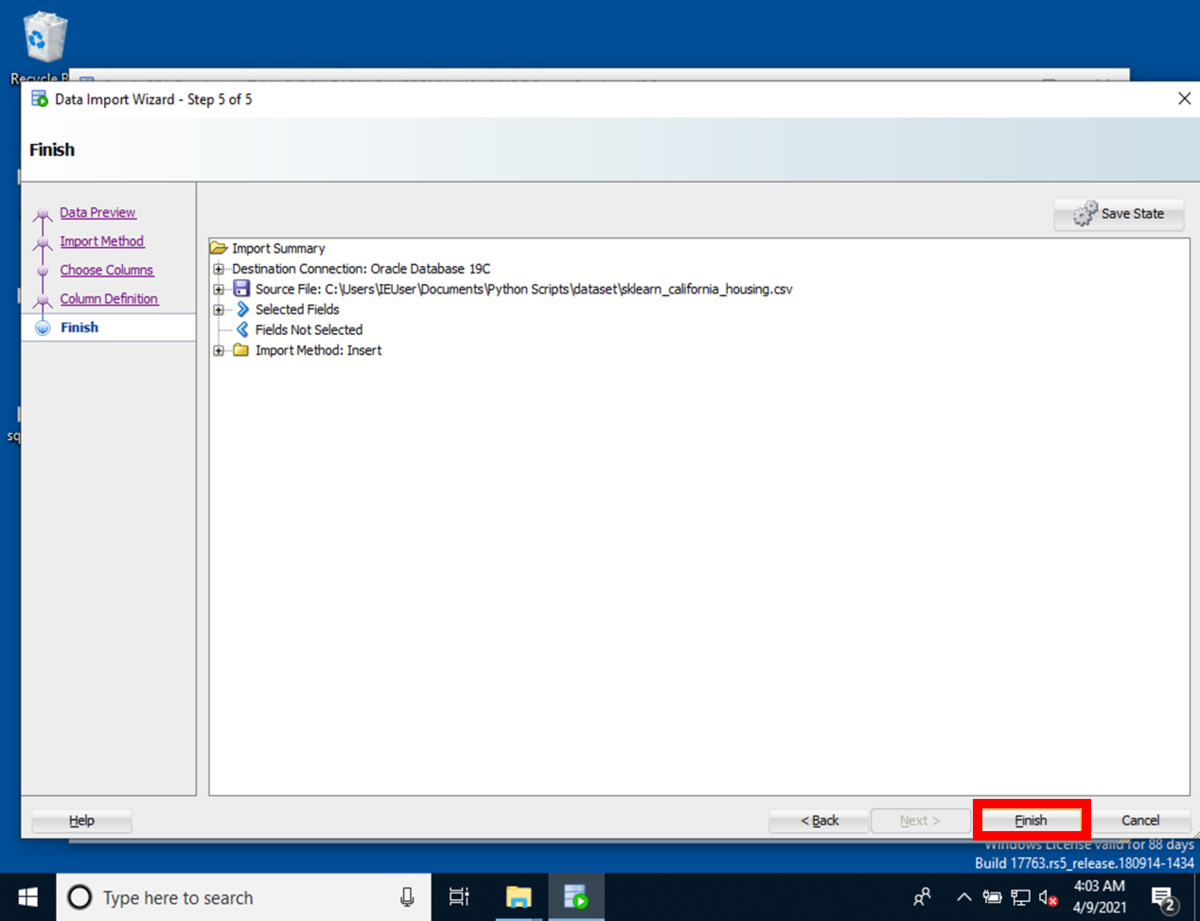
インポートが終了したImportData. Task successful and import committed.の表示を確認します。
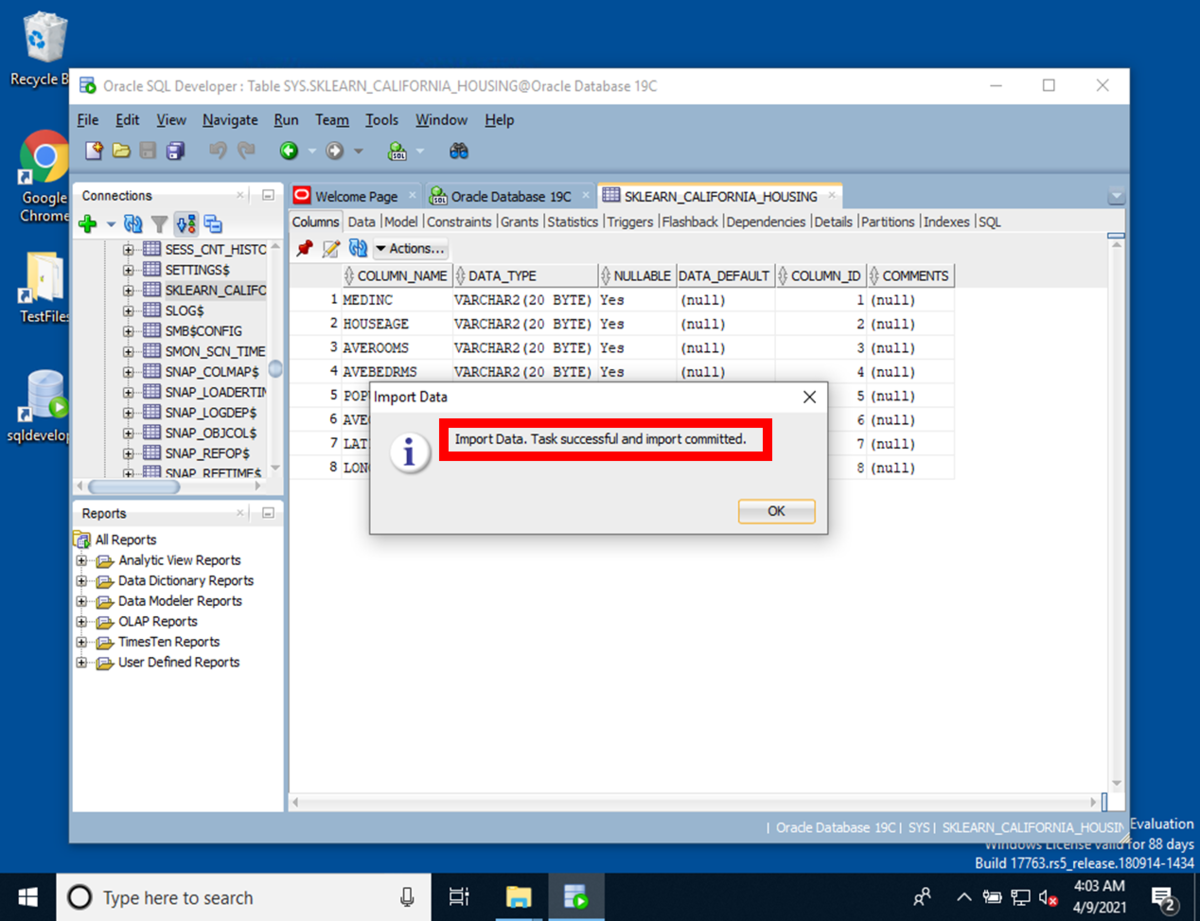
インポート終了後、データベースに値が入っていることが確認できます。
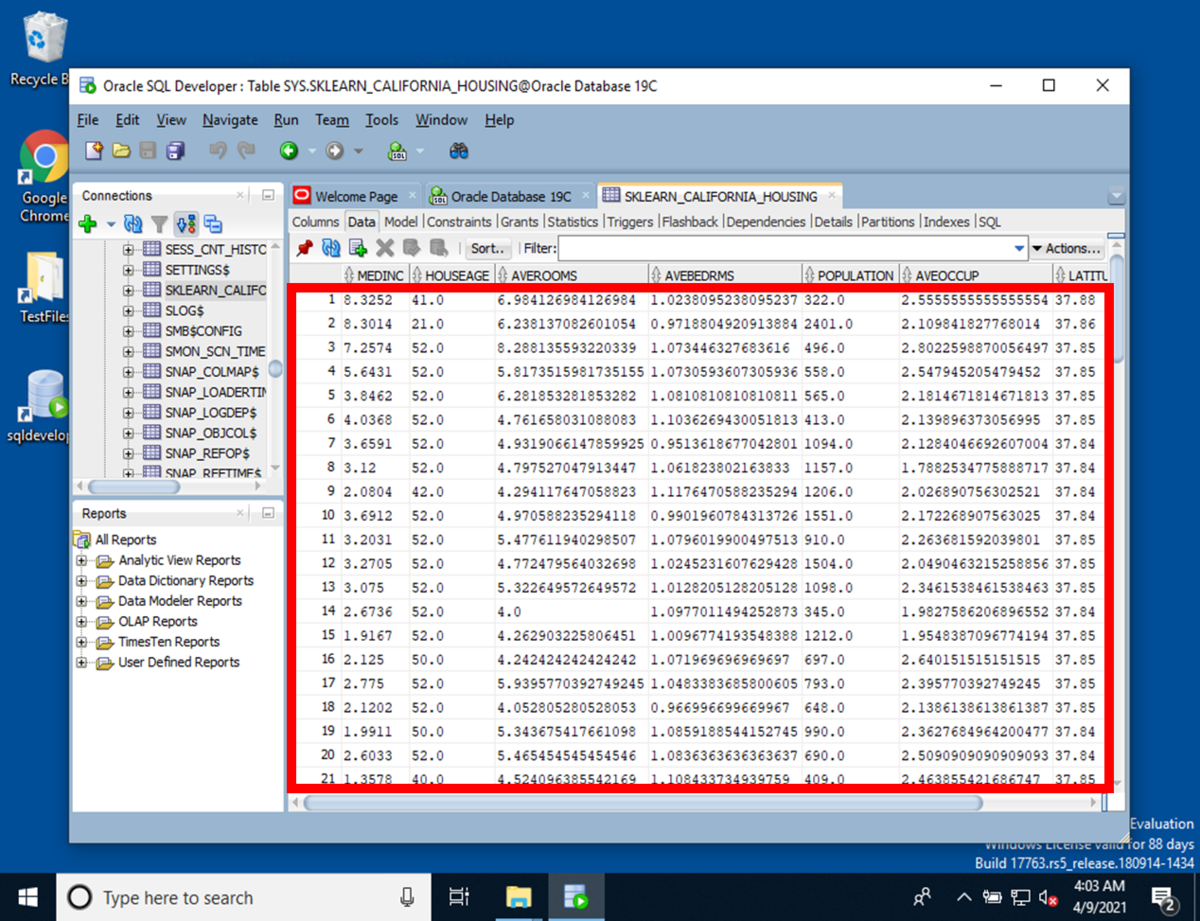
まとめ
以上が、PythonプログラムでOracle DatabaseからSalesforceにデータ連携するために必要なPython環境の構築、 Pythonライブラリのインストール方法、scikit-learnからデータ取得して、Oracle Databaseにデータをインポートする手順です。
この記事の範囲であるPythonプログラムのライブラリをインストールして、 Oracle Databaseに連携対象となるデータを連携するところまではできたと言えます。
理系のキャリア構築構築の場合、データベース連携などのインフラ連携や機械学習、 自然言語処理など分野に応じたプログラミングは、必須となってきています。
一般社団法人情報処理学会 - 会誌「情報処理」 - Vol.59 - No.4 - 私のターニングポイント -私はこれでキャリアを決めました-:編集にあたって
Salesforceは顧客管理システムとして著名なエンタープライズアプリケーションなので、 Salesforceと連携できればビジネスサイドとの連携も期待できます。 ご紹介したPythonライブラリやインストール方法が参考となれば幸いです。
次の記事では、Pythonスクリプトを使用して、Oracle DatabaseとSalesforceとの連携をご紹介させて頂きます。
Pythonプログラムと連携できると多くのインテグレーションパターンを検討することができます。 データベースからSalesforceに連携するプロジェクトで、紹介させて頂いたライブラリを使用することを検討してみて下さい。
よろしくお願いいたします。
備考
この記事は、著者が独自に調査した結果を、ロジカル・アーツ株式会社のブログにて記事化したものです。記載されている手順やアドレスなどは、予告なく変更される場合もあります。 この記事に記載されている会社名、商品名などは一般に各社の商標または登録商標です。なお、本文中には、™、®を明記しておりません。 クラウドアプリケーションは、成長が著しいため、機能更新も早いです。至らない箇所もあると思いますが、お気付きの点がありましたらお問い合わせ下さい。
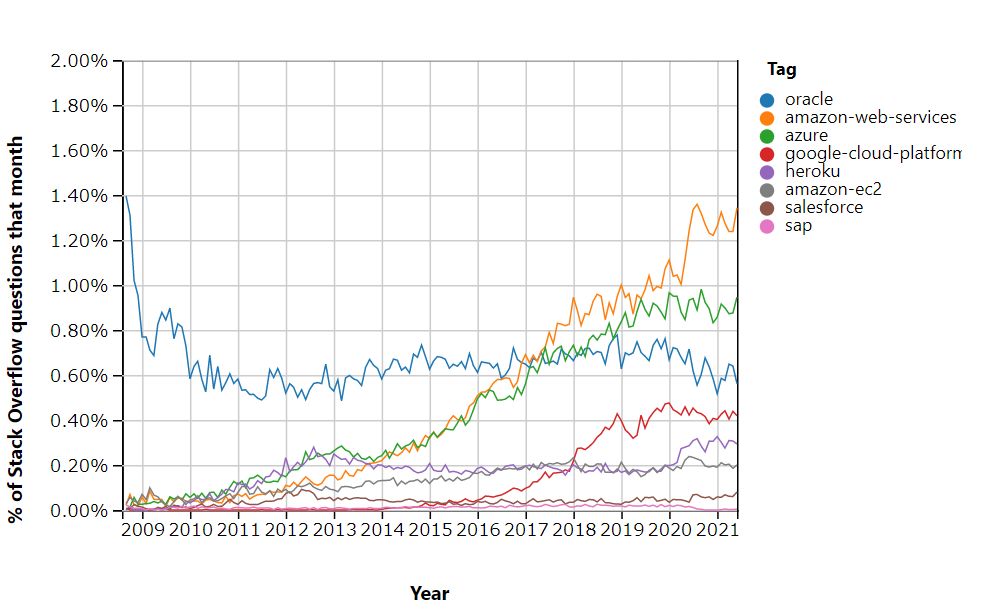
クラウドアプリケーショントレンド(参考)
Stack Overflow Insights - Stack Overflow Trends
Yahoo Finance - Salesforce.com Inc (CRM) Interactive Stock Chart
よろしくお願いいたします。