
こんにちは。ロジカル・アーツの福島です。
今回はAWSサービスの一つである、Amazon SageMaker Studioを使用して機械学習モデルを作成し、予測を行いたいと思います。
- はじめに
- Amazon SageMakerについて
- Step1:AWSアカウントを作成する
- Step2:Amazon SageMaker Studioをセットアップする
- Step3:データセットをダウンロードする
- Step4:SageMaker Autopilot実験を作成する
- Step5:Amazon SageMaker Autolpilot実験のさまざまなステージを調べる
- Step6:最適なモデルをデプロイする
- Step7:モデルを使用して予測を行う
- Step8:クリーンアップ
- まとめ
はじめに
この記事では「AWS SageMaker Studioに触れ、基本的な利用方法を知る」ことを目的としています。そのため、構築の手順はAWSが公開している「機械学習モデルを自動的に作成する」を参考にしています。 このチュートリアルに沿って、以下の手順で進めていきます。
- AWS アカウントを作成する
- Amazon SageMaker Studioをセットアップする
- データセットをダウンロードする
- Amazon SageMaker Autopilot実験を作成する
- Amazon SageMaker Autolpilot実験のさまざまなステージを調べる
- 最適なモデルをデプロイする
- モデルを使用して予測を行う
- クリーンアップ
チュートリアル上では、所要時間は10分と記載されていますが、実際にはモデルの最適化などを含めて1~2時間程度かかります。また、料金が発生するサービスを使用しているため、Step8にて今回使用したサービスを終了する手順を記載しています。途中で作業を中断・終了される際はそちらを参考にしてください。
なお、今回使用するチュートリアルは本記事作成時点のものを参考にしています。仕様や料金体系が変更されている可能性がありますのでご注意ください。
Amazon SageMakerについて
Amazon SageMakerは、AWSが提供している機械学習用のサービスや機能をコンソール上で操作することで機械学習モデルを高速で準備・構築・トレーニングおよびデプロイを行うことができるサービスです。 その中でも今回使用するAmazon SageMaker StudioとAmazon SageMaker Autopilotについて軽く紹介したいと思います。
Amazon SageMaker Studio
Amazon SageMaker Studioはすべての開発ステップを単一のインターフェースで実行できる統合開発環境(IDE)です。
ローカルで開発を行う際には環境構築、データの準備と整形、学習の実行、ハイパーパラメータの調整など手間のかかる作業が多くあります。また、解決すべき問題に合わせて可視化ツールを用意したり、最適なパターンを試すうちにファイルが煩雑になったりという問題もあります。
Amazon SageMaker Studioでは開発・学習・予測の大部分の作業をStudio上で完結させることができます。Amazon SageMakerが提供するサービスをインターフェース上で実行できるので、ハイパーパラメータの自動調整や、関連するデータやファイルの管理、問題に合わせた可視化ツールを簡単に使用することができるようになります。
Amazon SageMaker Autopilot
Amazon SageMaker Autopilotは回帰/分類問題に対して、自動で機械学習モデルの準備、トレーニングおよびパラメータ調整を行ってくれます。
ローカル環境でトレーニングおよび調整を行う場合、数十~数百のパターンのモデル/アルゴリズム選択やパラメータ調整を手動で行っており、機械学習モデルに対する深い専門知識が必要でした。
Autopilotでは、表形式のデータセットを準備し、予測するターゲットの列を指定するだけで自動的にモデルの構築、トレーニングおよび調整を行います。
それでは、実際にこれらのサービスを使用してモデルの構築~予測を行っていきます。
Step1:AWSアカウントを作成する
AWSアカウントの作成につきましては、AWS公式サイトの「AWSにサインアップ」から作成を行ってください。既にアカウントをお持ちの方はサインインを行ってください。
Step2:Amazon SageMaker Studioをセットアップする
Amazon SageMakerコンソールにサインインし、リージョンが東京であることを確認してください。
※東京以外のリージョンで行う場合、リージョンの指定がある箇所をap-northeast-1から書き換える必要があるので注意してください。
次に、「Open Amazon SageMaker Studio」を押下してください。
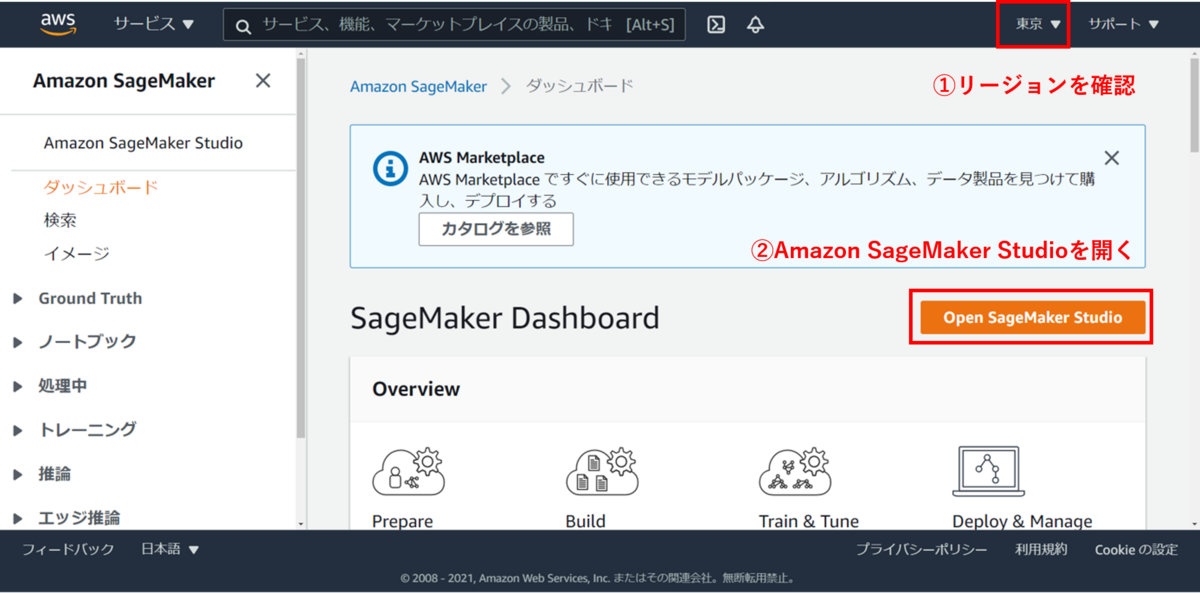
すると、セットアップ画面に移動します。 セットアップにはクイックスタートと標準セットアップがあります。
クイックスタートは標準セットアップのデフォルト設定であり、ユーザー名とIAMロールを選択することですぐにセットアップが完了する方法です。認証方法はIAMとなります。
標準セットアップはより詳細な設定が可能であり、認証方法もIAMに加えてSSO(Single Sign-On)が使用できます。 詳細につきましてはOnboard to Amazon SageMaker Studioをご覧ください。
今回はクイックスタートで設定を行います。ユーザー名は任意のものを設定してください。IAMロールは「新しいロールの作成」から「任意のS3バケット」を選択し作成します。
その他はいじらずに、送信します。そのまま数分待つとSageMaker Studioが作成されます。
Step3:データセットをダウンロードする
今回使用する内容は、銀行を利用する顧客が預金証書の申し込みを行うかどうか(yes/no)の二値分類です。モデルの学習には各種情報を含んだマーケティングデータセットを扱います。
SageMaker Studioを準備する
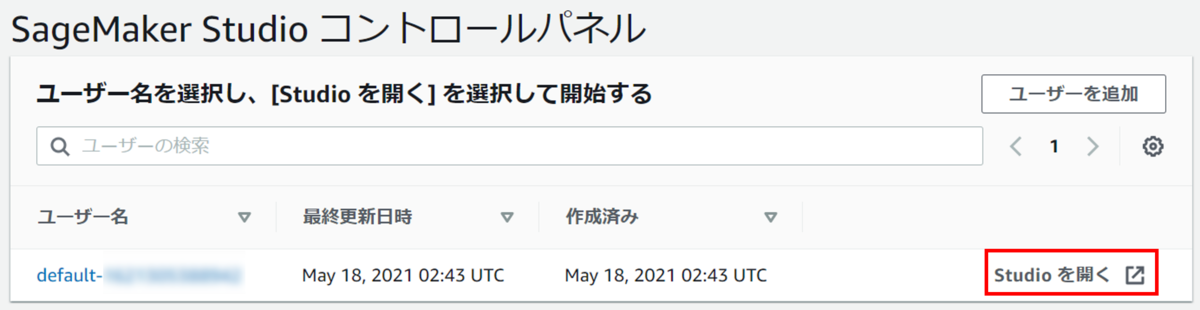
SageMaker Studioコントロールパネルから、先ほど作成したユーザーの右にある「Studioを開く」を選択してください。(最初はサーバー作成などでStudioを開くまで数分かかります)
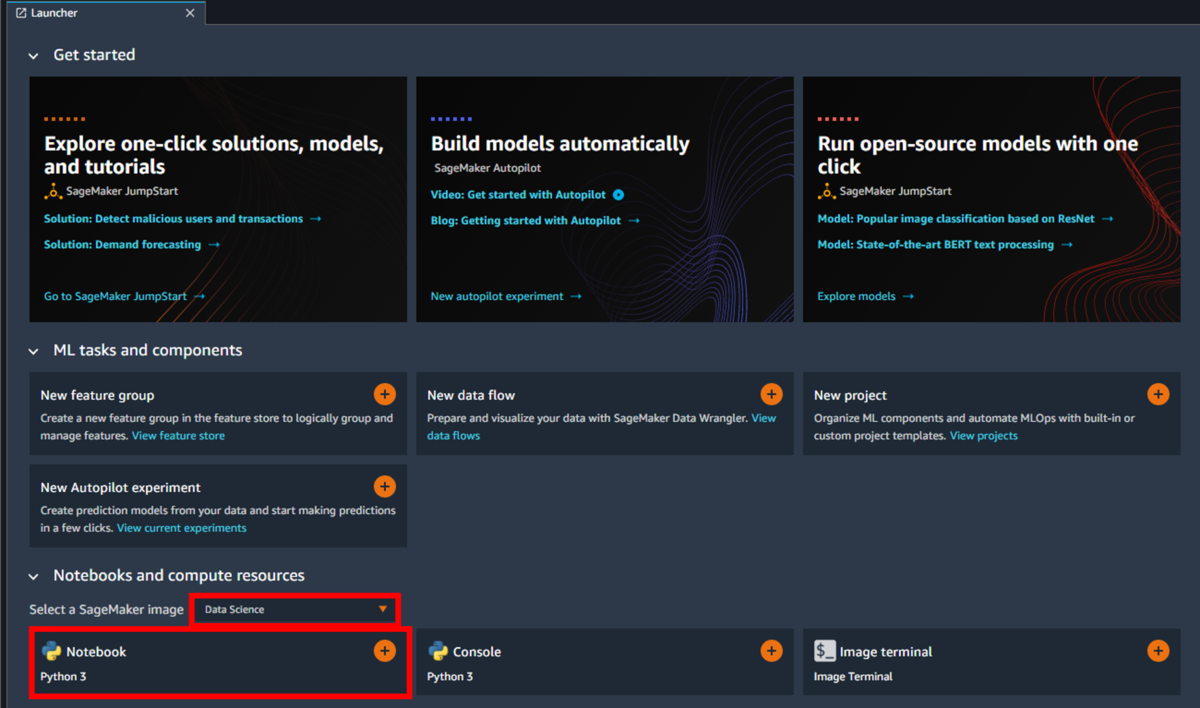
起動したらLauncher内の「Notebooks and compute resources」にある「Select a SageMaker image」がData Scienceであることを確認し、Python3 Notebookを選択してください。
データセットを取得する
今回はチュートリアルとして用意されているデータセットを扱うので、以下のコードを貼り付け、実行します。(画面上部の再生ボタンまたはShift + Enter)
%%sh apt-get install -y unzip wget https://sagemaker-sample-data-us-west-2.s3-us-west-2.amazonaws.com/autopilot/direct_marketing/bank-additional.zip unzip -o bank-additional.zip
※注意:上記のコードでreturned a non-zero codeなどのエラーが出る場合、apt-get updateを最初に書き加えて実行してみてください。
データセットを読み込み、正常にダウンロードできているか確認する
さらに、以下のコードを貼り付け実行します。
import pandas as pd data = pd.read_csv('./bank-additional/bank-additional-full.csv') data[:10]
このコードでは、CSVデータセットを読み込み、最初の10行を表示しています。以下のように表示されていれば正しくダウンロードし、読み込まれています。

データセットをS3にアップロードする
以下のコードを貼り付け、実行してください。
import sagemaker prefix = 'sagemaker/tutorial-autopilot/input' sess = sagemaker.Session() uri = sess.upload_data(path="./bank-additional/bank-additional-full.csv", key_prefix=prefix) print(uri)
この手順では、CSVデータセットをS3バケットにアップロードしています。アップロード時にSageMakerが自動的にデフォルトバケットを用意するので、ユーザーが手動でバケットを作成する必要はありません。
以下のようなS3バケットのURIが出力されていれば成功です。ただし、ACCOUNT_NUMBERの箇所には使用しているAWSアカウントが表示されています。
s3://sagemaker-ap-northeast-1-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/input/bank-additional-full.csv
Step4:SageMaker Autopilot実験を作成する
環境構築とデータセットの準備が完了したので、Amazon SageMaker Autopilotの設定を行います。この実験は1~2時間程度かかりますので、注意してください。
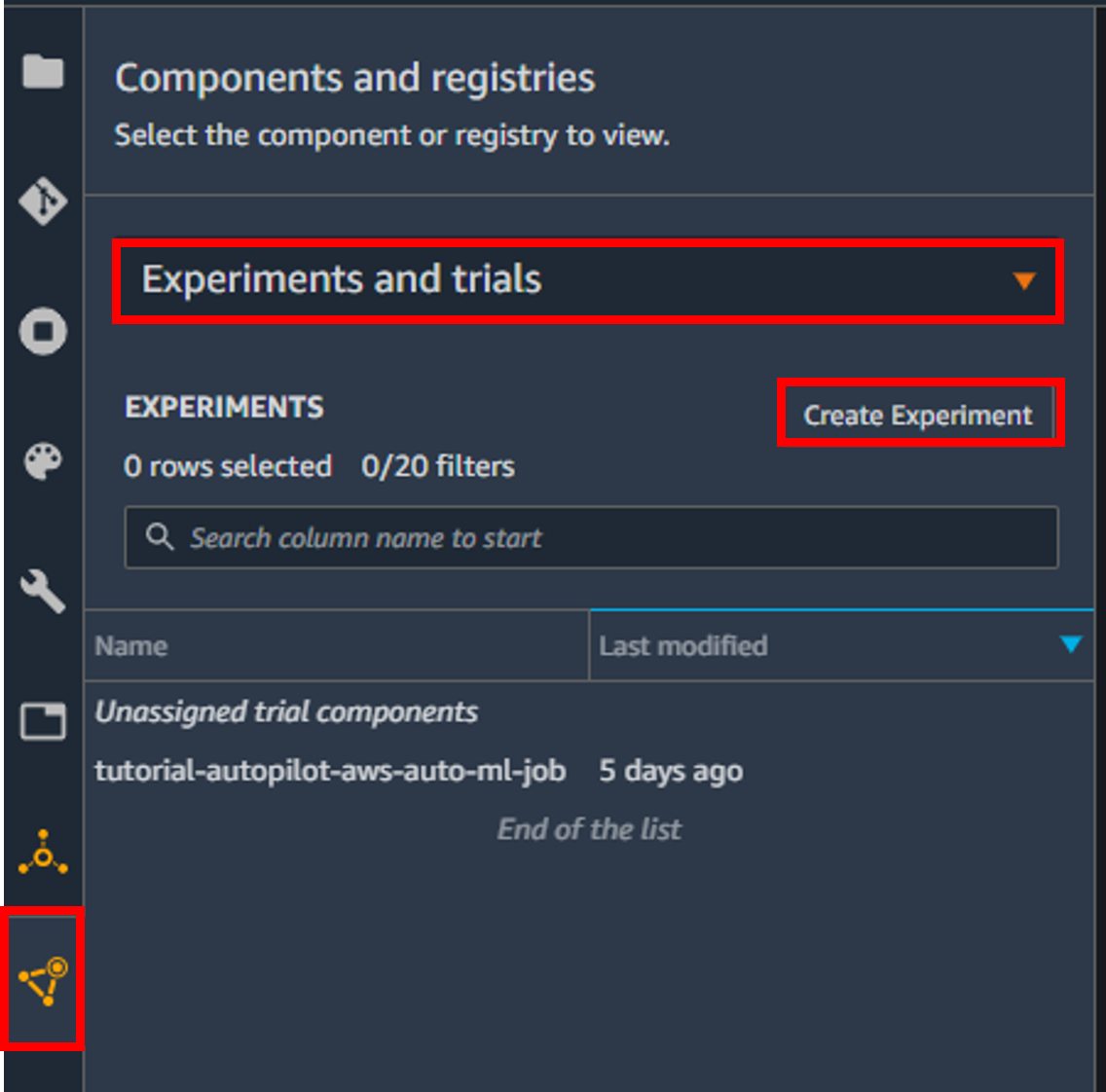
まずは、画面左部にあるナビゲーションバーのうち、一番下の三角形のアイコンを選択します。
次に、「Projects」と表示されているプルダウンメニューを押し、「Experiments and trials」を選択します。
プルダウンメニュー下部に「Create Experiments」というボタンが表示されるので、選択します。
実験の設定は、以下のように行います。下記以外の設定についてはデフォルトです。
| 項目 | 設定 |
|---|---|
| Experiment name | tutorial-autopilot |
| CONNECT YOUR DATA | - Enter S3 bucket location - S3 bucket address:s3://sagemaker-ap-northeast-1-[ACCOUNT_NUMBER]/sagemaker/tutorial-autopilot/input/bank-additional-full.csv |
| Target | y |
| Output data location (S3 bucket) | - Enter S3 bucket location - S3 bucket address:s3://sagemaker-ap-northeast-1-[ACCOUNT_NUMBER]/sagemaker/tutorial-autopilot/input |
全ての入力が完了したら、画面下部の「Create Experiment」を選択します。
自動でモデルの最適化を行います。この作業が完了するまで1~2時間程度かかります。
Step5:Amazon SageMaker Autolpilot実験のさまざまなステージを調べる
実験の完了まで1~2時間かかるので、その間に実験のステージについて調べてみましょう。
ステージは大きく分けて以下の3つがあります。
- データの分析
- 特徴量エンジニアリング
- モデルチューニング
データの分析
このステージでは、与えられた表形式のデータセットから、問題のタイプを特定します。(線形回帰、二項分類、多項分類など)
その後、候補となるパイプラインを10個表示します。パイプラインには、以下の2ステップの組み合わせが定義されています。
特徴量エンジニアリング
このステージでは、前ステージで作成されたパイプライン用に学習データセットと検証データセットを作成し、特徴量抽出を行います。 また、2つのノートブックが自動生成されます。
データ探索ノートブック
データセットの情報や学習結果、統計が含まれています。候補生成ノートブック
10個のパイプラインの定義が含まれています。前処理とアルゴリズムの組み合わせ、ハイパーパラメータ調整の手法が記述されており、実行手順も書かれています。
これら2つのノートブックを参照することで、ブラックボックス化しやすいモデルの構築や最適化の透明性を向上させ、機械学習への理解を深めることができます。
モデルチューニング
このステージでは、今までの実験の結果を利用してハイパーパラメータ最適化が行われます。このステージが終了すると実験は完了です。
Step6:最適なモデルをデプロイする
実験が完了したので、最適なモデルをエンドポイントにデプロイします。
「Objective」の列をソートします。そして、星がついている最適なモデルの行を選択し「Deploy Model」を選択します。
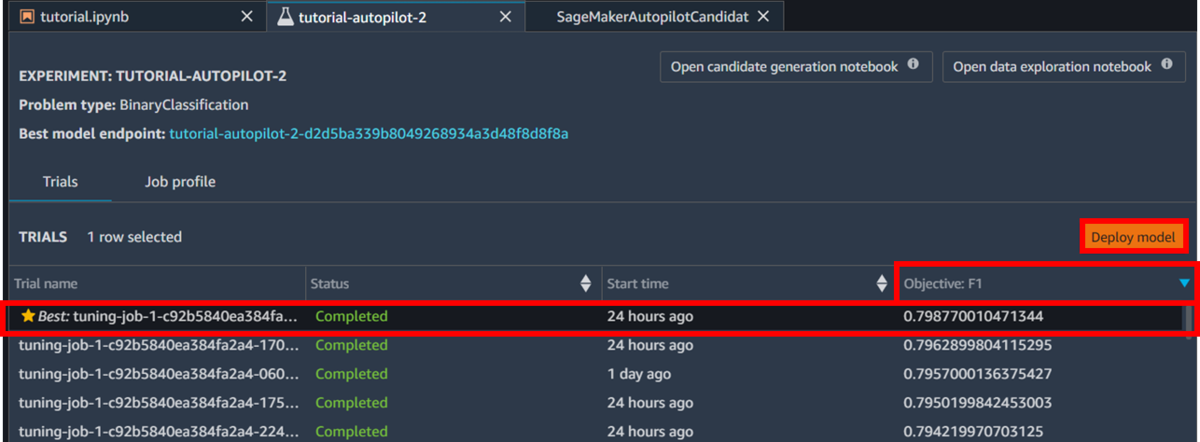
エンドポイント名を入力し、他の設定はデフォルトのまま「Deploy Model」を選択するとデプロイを開始します。
画面左部のサイドメニューのプルダウンの部分を「Endpoints」に変更すると、モデルの状態を確認することができます。 モデルの作成には数分かかります。「InService」の状態になったらデータを送信し、予測を行うことができます。
Step7:モデルを使用して予測を行う
エンドポイントにモデルのデプロイができたので、実際に予測を行っていきます。
以下のコードを貼り付け、実行してください。
なお、コード内のep_nameはStep6で命名したエンドポイント名であることに注意してください。
import boto3, sys ep_name = 'tutorial-autopilot-best-model' sm_rt = boto3.Session().client('runtime.sagemaker') tn=tp=fn=fp=count=0 with open('bank-additional/bank-additional-full.csv') as f: lines = f.readlines() for l in lines[1:2000]: # Skip header l = l.split(',') # Split CSV line into features label = l[-1] # Store 'yes'/'no' label l = l[:-1] # Remove label l = ','.join(l) # Rebuild CSV line without label response = sm_rt.invoke_endpoint(EndpointName=ep_name, ContentType='text/csv', Accept='text/csv', Body=l) response = response['Body'].read().decode("utf-8") #print ("label %s response %s" %(label,response)) if 'yes' in label: # Sample is positive if 'yes' in response: # True positive tp=tp+1 else: # False negative fn=fn+1 else: # Sample is negative if 'no' in response: # True negative tn=tn+1 else: # False positive fp=fp+1 count = count+1 if (count % 100 == 0): sys.stdout.write(str(count)+' ') print ("Done") accuracy = (tp+tn)/(tp+tn+fp+fn) precision = tp/(tp+fp) recall = tn/(tn+fn) f1 = (2*precision*recall)/(precision+recall) print ("%.4f %.4f %.4f %.4f" % (accuracy, precision, recall, f1))
以下のような出力が表示されれば成功です。
100 200 300 400 500 600 700 800 900 1000 1100 1200 1300 1400 1500 1600 1700 1800 1900 Done 0.9915 0.7551 0.9974 0.8595
このコードではデータセットの2000個のサンプルを予測しています。1行目は進捗を表しており、予測が100個終わるごとに表示しています。
2行目の数字は左から精度、適合率、再現率、F値です。
| 実際の値 | |||
| 正 | 負 | ||
| 予測した値 | 正 | TP (True Positive) |
FP (False Positive) |
| 負 | FN (False Negative) |
TN (True Negative) |
|
予測されたラベルを上記のように分類するとき、この4つの数値は以下で表せます。
- 精度(Accuracy):正や負と予測したデータのうち、実際にそうであるものの割合
- 適合率(Precision):正と予測したデータのうち、実際にそうであるものの割合
- 再現率(Recall):実際に正であるもののうち、正であると予測されたものの割合
- F値(F-measure):再現率と適合率の調和平均
Step8:クリーンアップ
チュートリアルが終了したので、不要なサービスを削除します。
以下の2つのコードをノートブックに貼り付けて、実行してください。 但し、2つ目のコードにある「ACCOUNT_NUMBER」は使用しているAWSアカウントのものである必要があるので、注意してください。
sess.delete_endpoint(endpoint_name=ep_name)
%%sh
aws s3 rm --recursive s3://sagemaker-ap-northeast-1-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/
これらはそれぞれ
- エンドポイントの削除
- S3バケットにあるデータを削除
という操作を行っています。
S3バケット自体を削除する場合は、S3のマネジメントコンソールへ移動し、バケットの削除を行いましょう。 sagemaker-studioとprefixがあるS3バケットを選択し、「空にする」を実行してバケット内を空にしてから「削除」を選択して完全に削除を行ってください。

Amazon SageMaker Studioが不要な場合はSageMaker Studioのコントロールパネルに移動し、ユーザー名を選択してください。
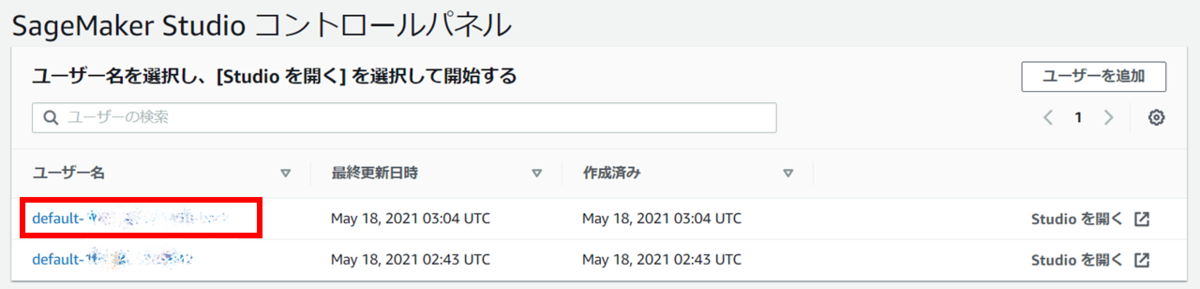
「アプリを削除」からStudio内のアプリケーションを削除し、Deletedとなったら「ユーザーを削除」を選択して削除してください。
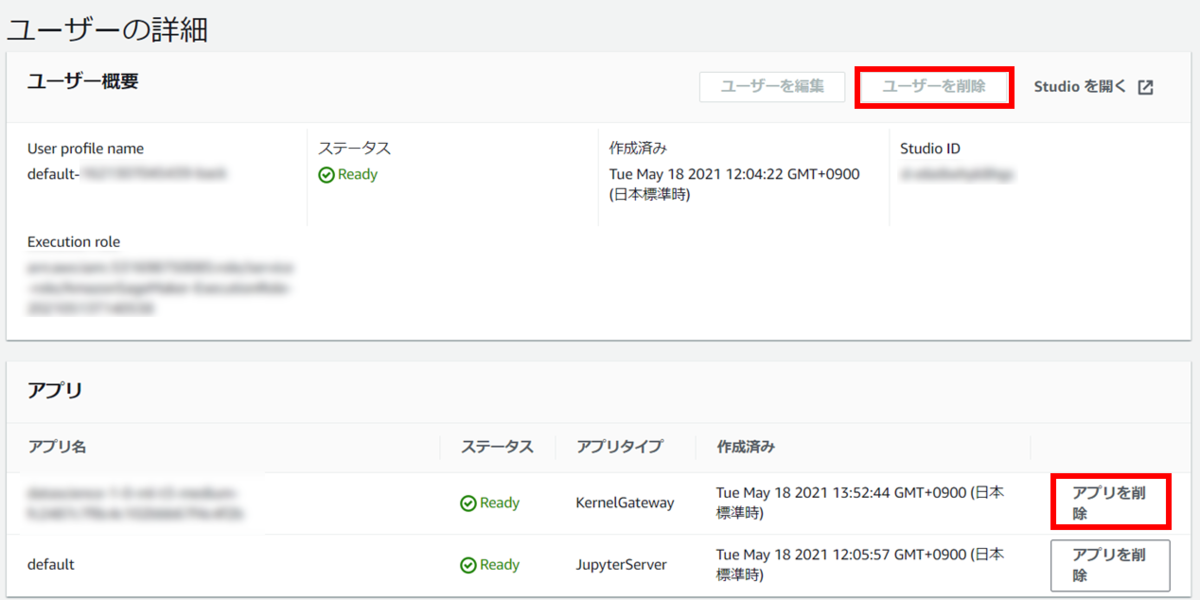
最後に、コントロールパネル上で「Studioを削除」とあるので、選択し実行すればStudioを削除できます。
まとめ
今回は、Amazon SageMaker Studioを使用して簡単な二値分類の機械学習モデルを構築・最適化して予測を行いました。 本来であれば複雑な構築やハイパーパラメータの設定も、簡単に行うことができるのが最大の利点かと思います。
AWSにはAmazon SageMaker以外にも機械学習をサポートする様々なサービスがあります。それらを組み合わせることでより高度なサービスを簡単かつ高速に展開できるようになるので、非常に魅力的です。 今後、そのようなサービスも使いこなせるよう勉学に励んでいきたいと思います。